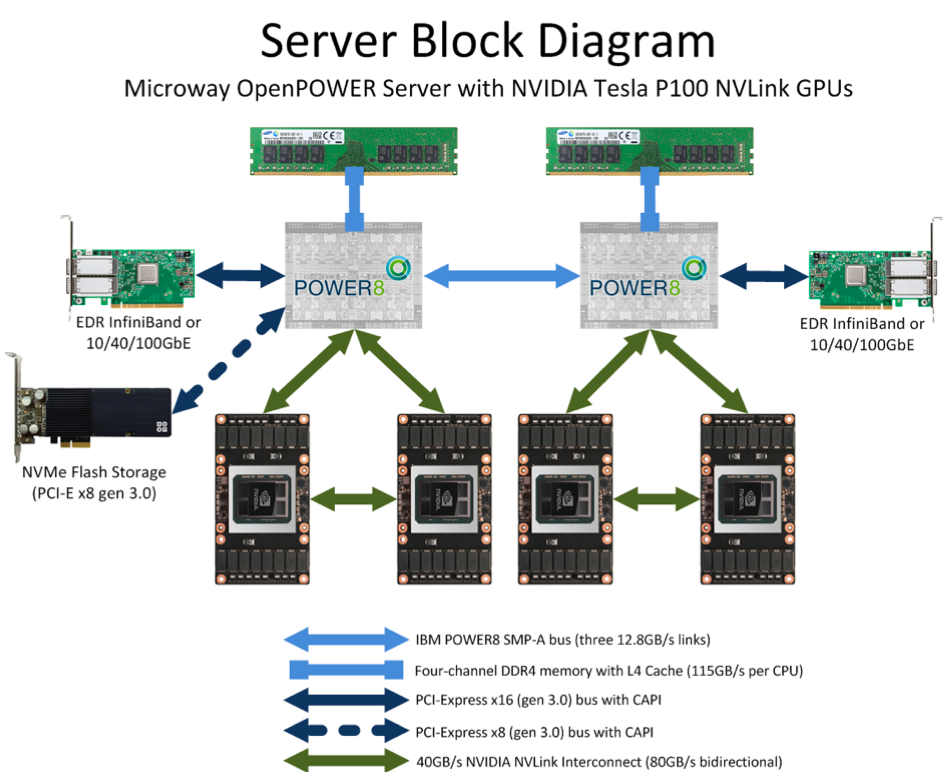
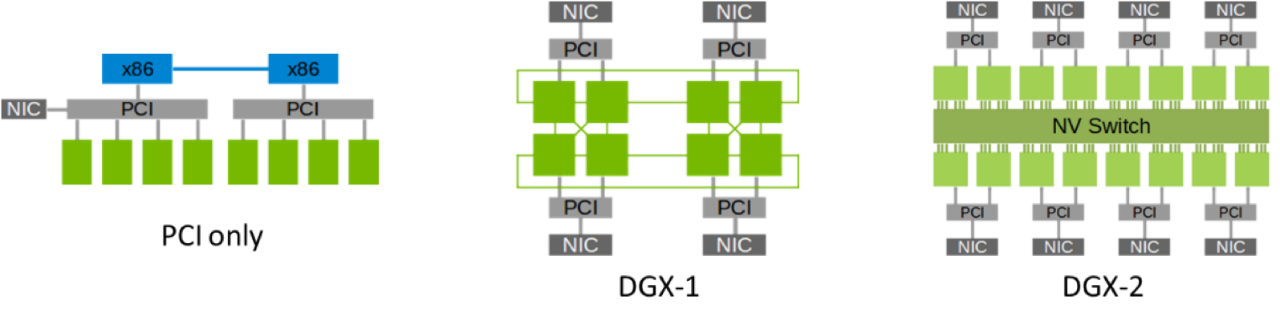
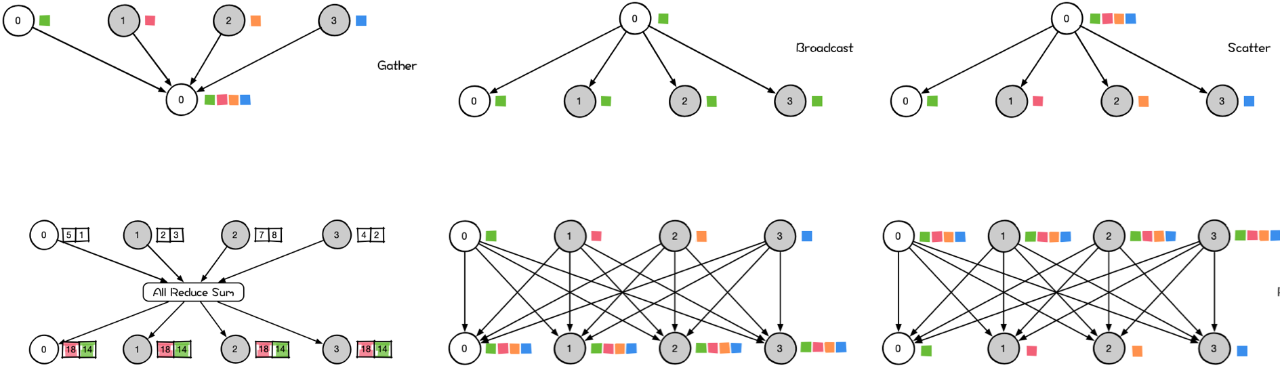
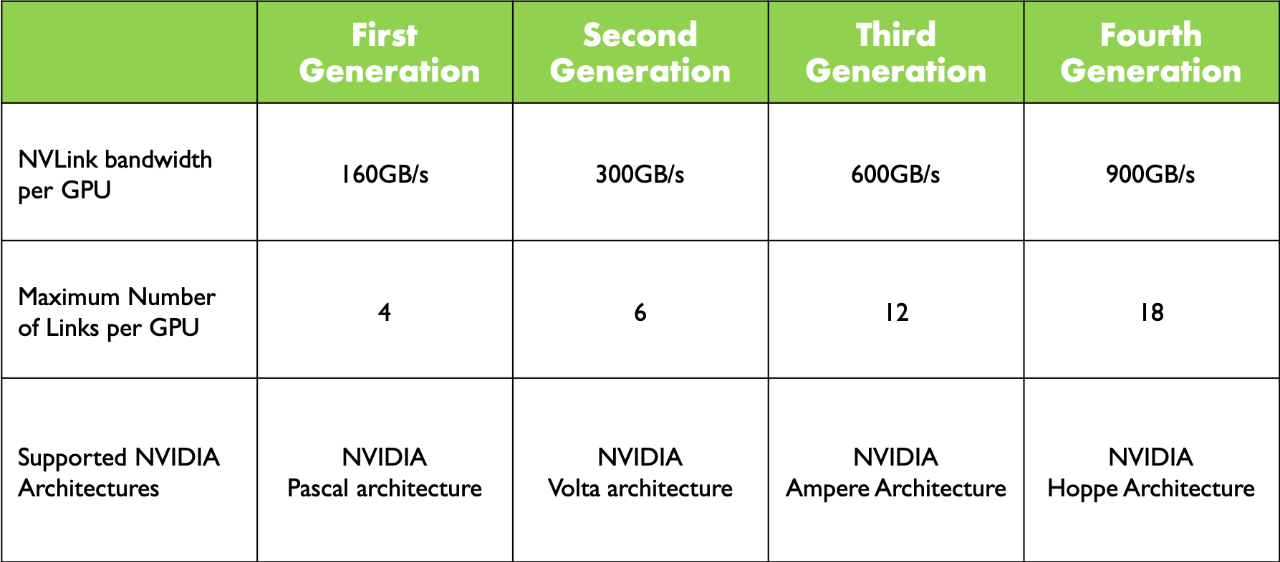
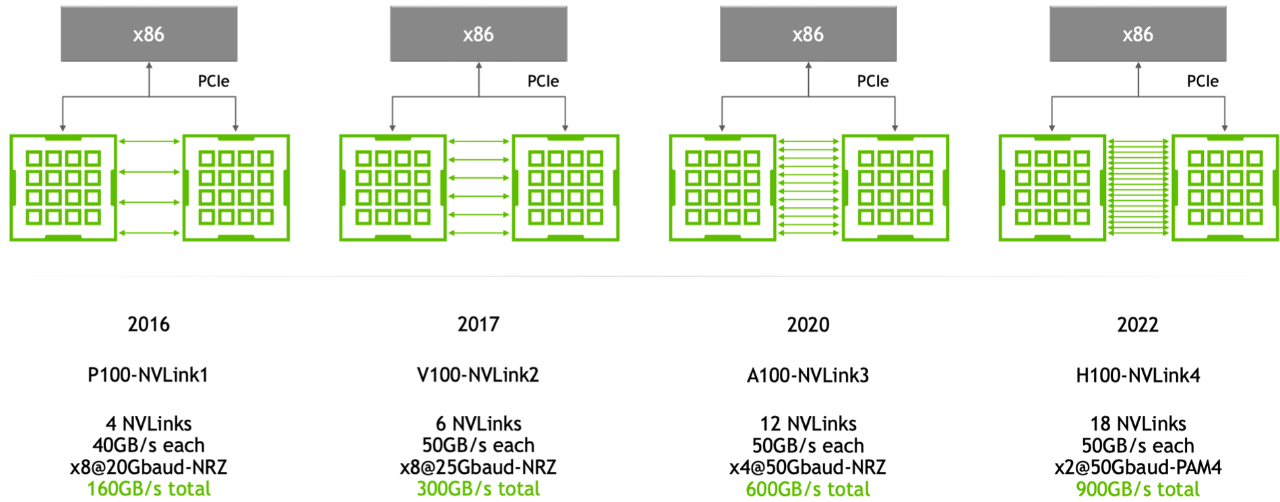
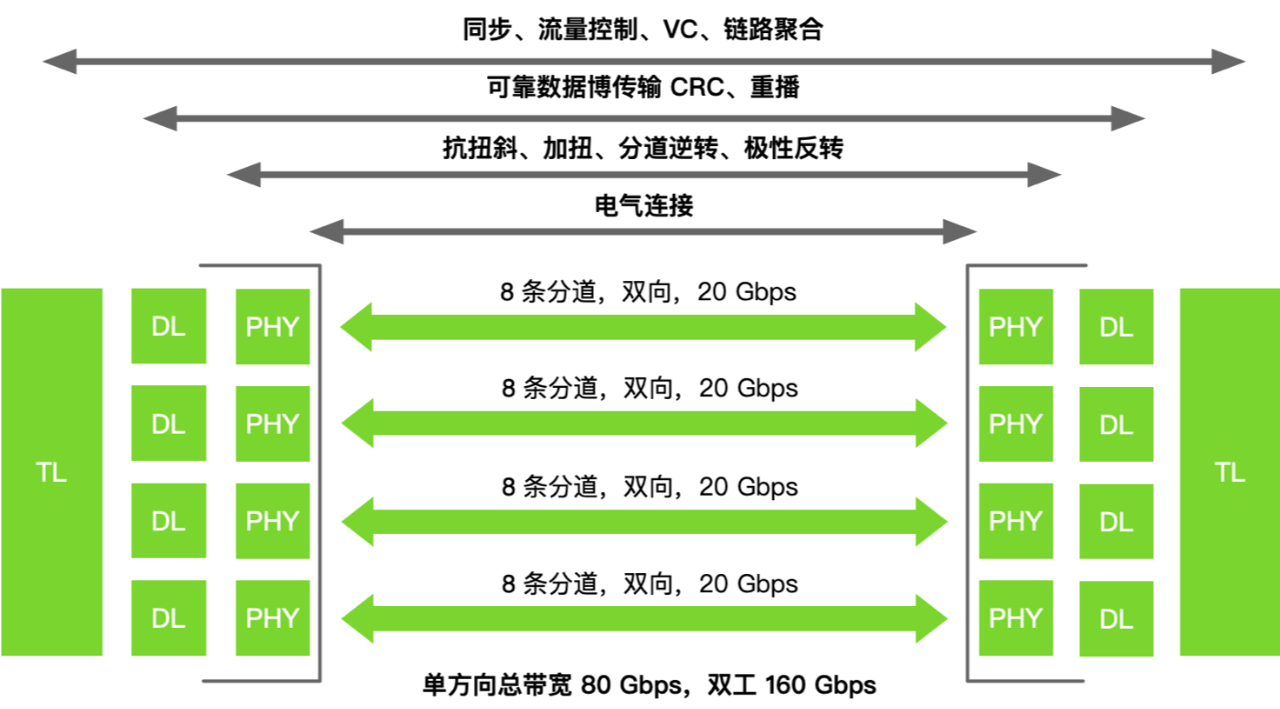
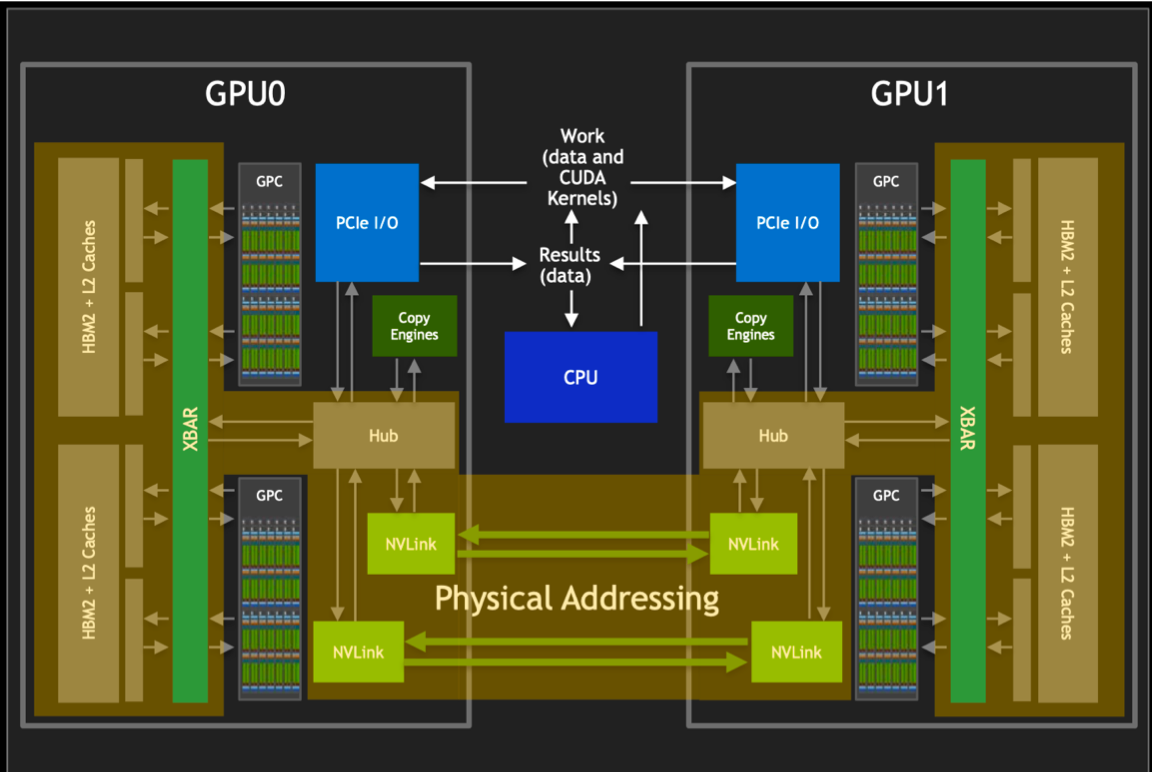
 在进入大模型时代后,大模型发展已是人工智能的核心,但训练大模型实际上是一项比较复杂的工作,因为它需要大量的 GPU 资源和较长的训练时间。此外,由于单个 GPU 工作线程的内存有限,并且许多大型模型的大小已经超出了单个 GPU 的范围。所以就需要实现跨多个 GPU 的模型训练,这种训练方式就涉及到了分布式通信和 NVLink。 当谈及分布式通信和 NVLink 时,我们进入了一个引人入胜且不断演进的技术领域,下面我们将简单介绍分布式通信的原理和实现高效分布式通信背后的技术 NVLink 的演进。 分布式通信是指将计算机系统中的多个节点连接起来,使它们能够相互通信和协作,以完成共同的任务。而 NVLink 则是一种高速、低延迟的通信技术,通常用于连接 GPU 之间或连接 GPU 与其他设备之间,以实现高性能计算和数据传输。
|





{kind=link}