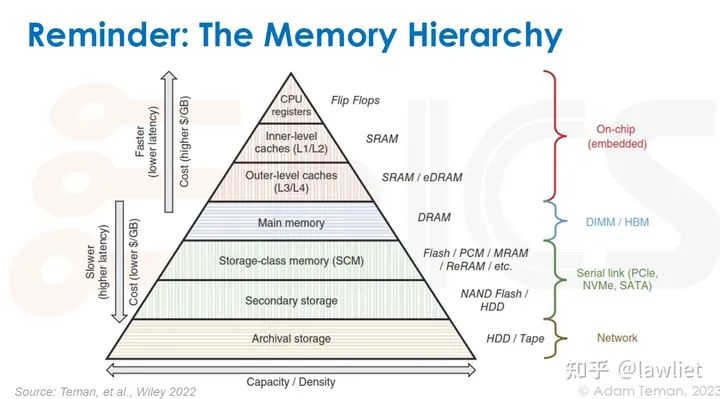
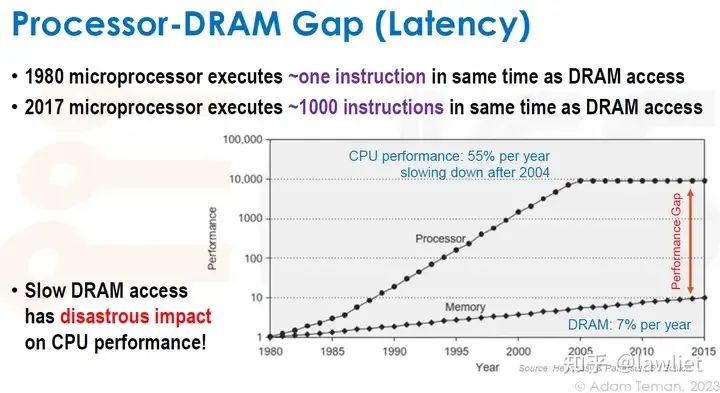
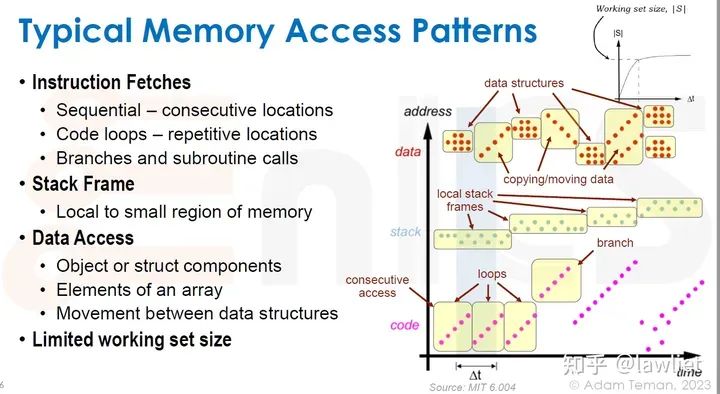
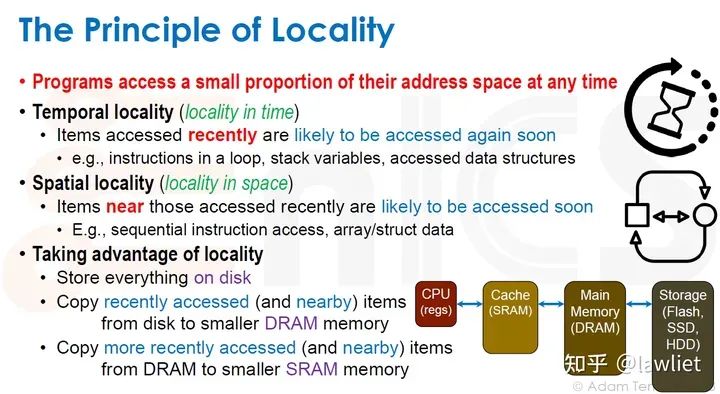
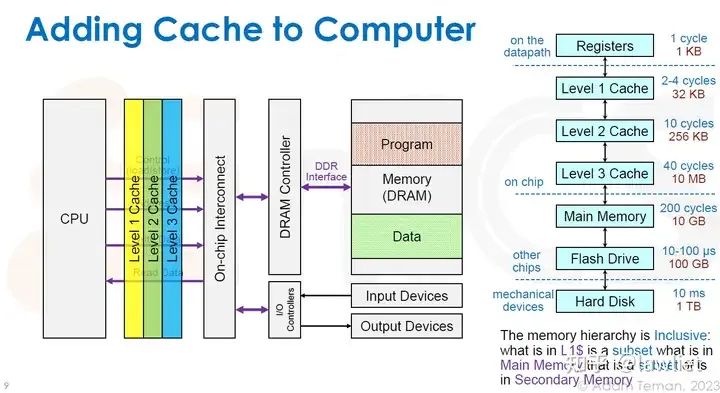
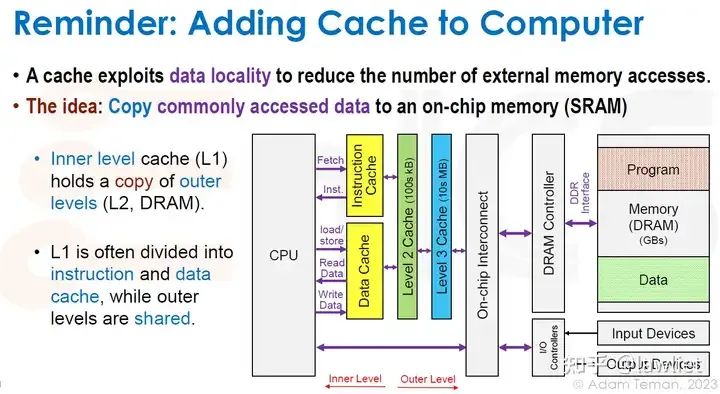
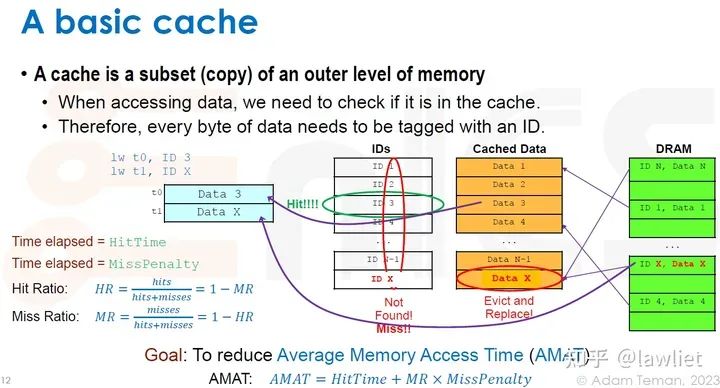
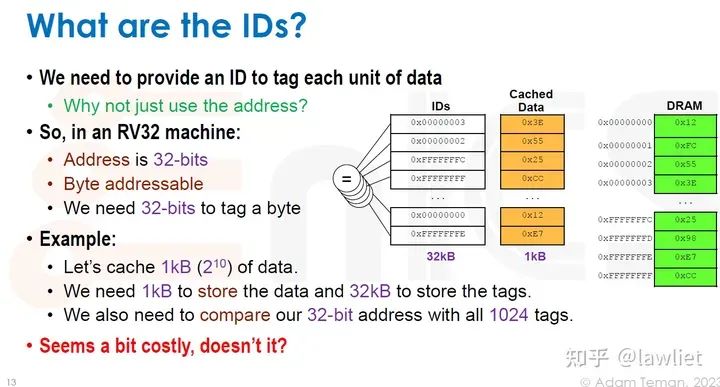
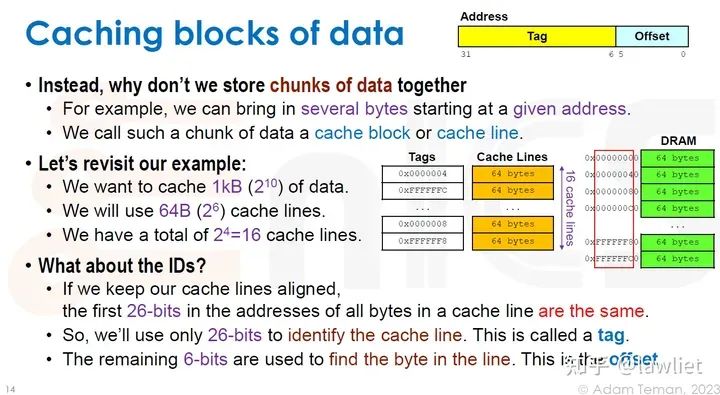
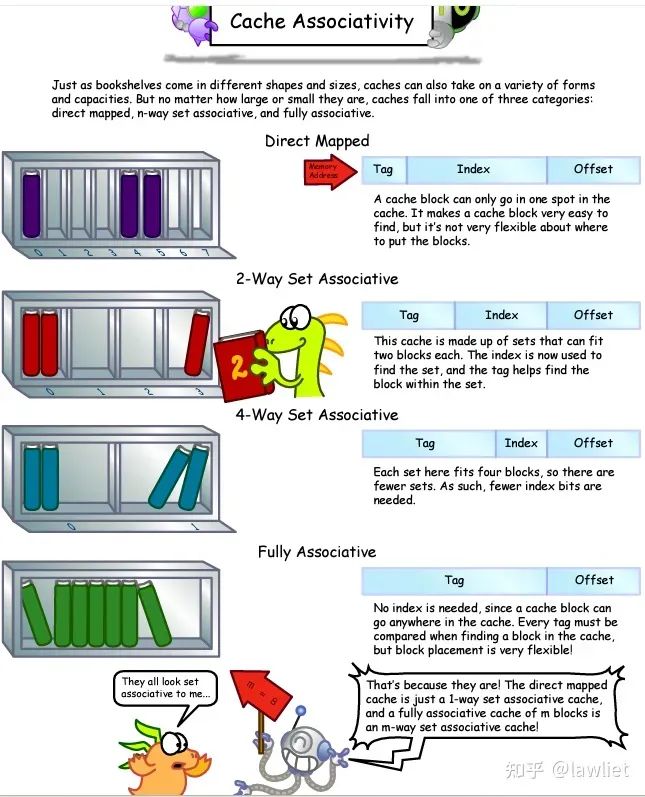
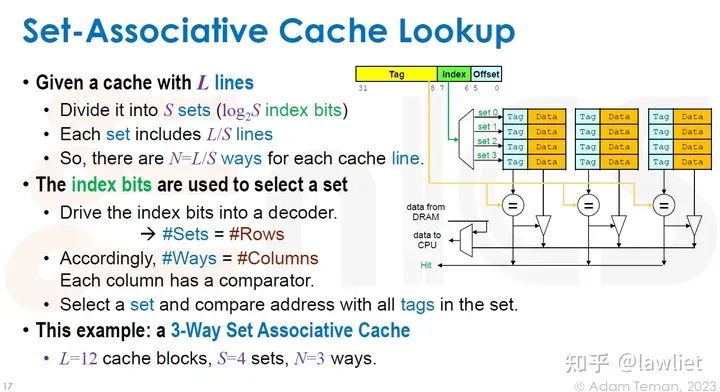
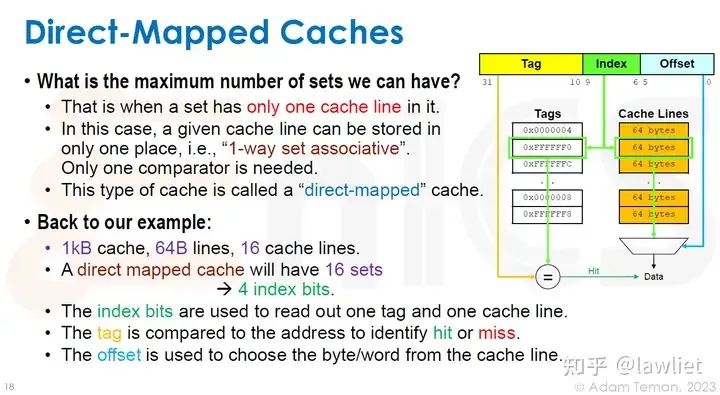
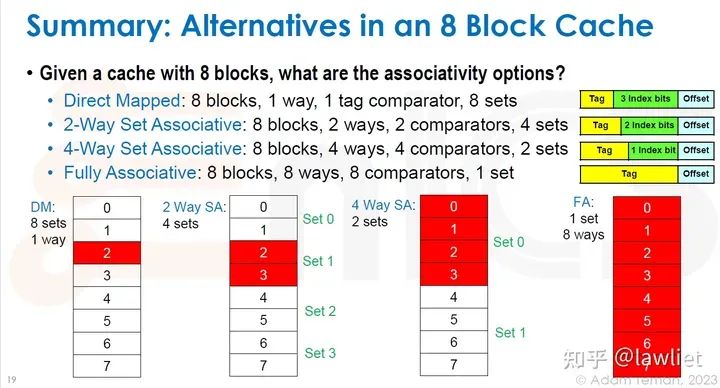
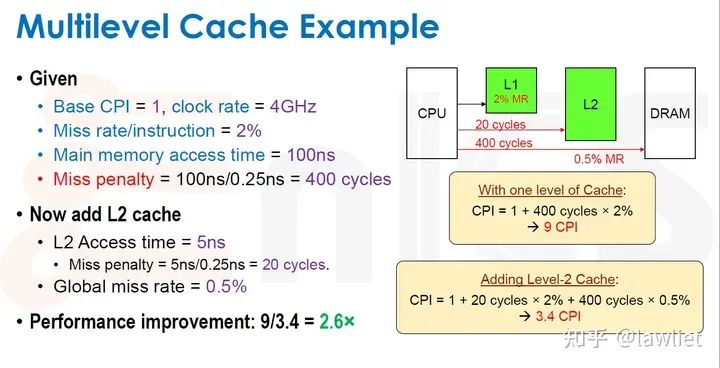
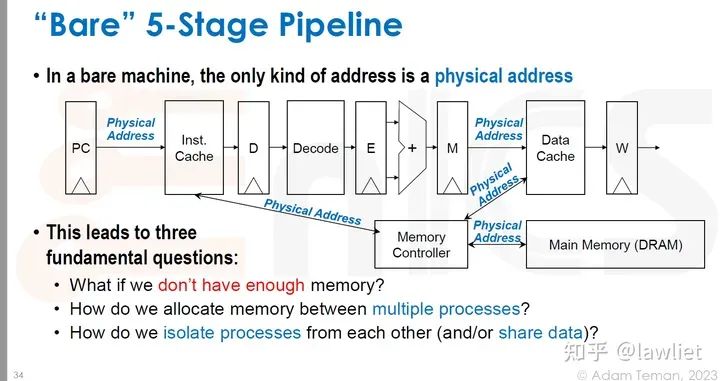
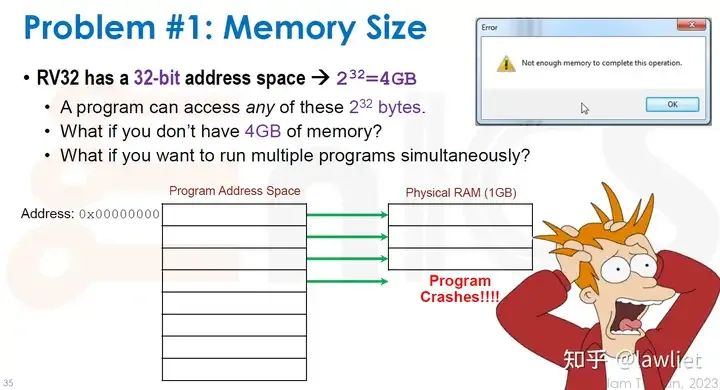
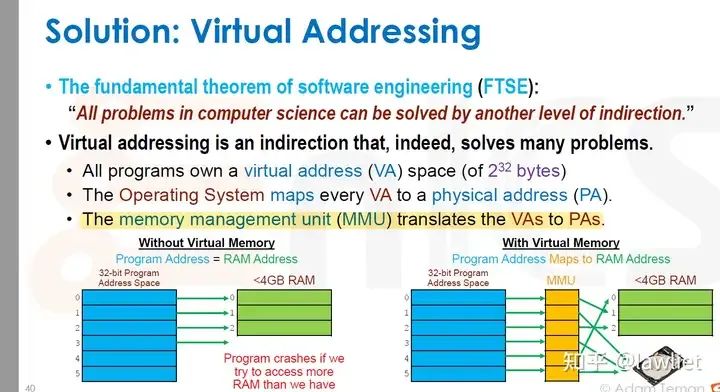
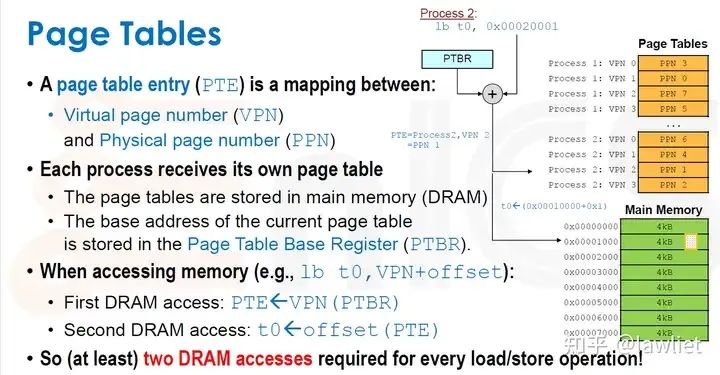
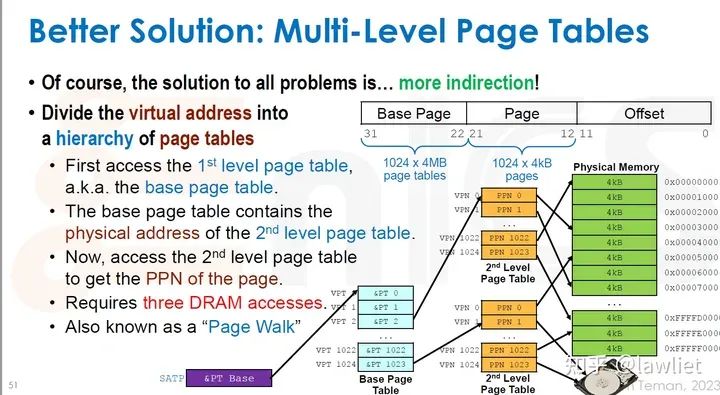
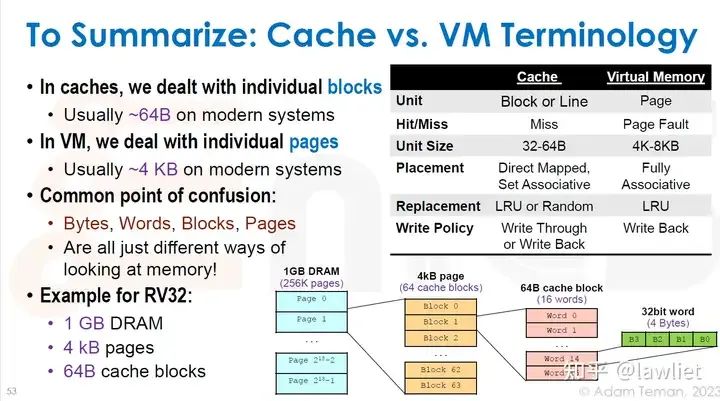
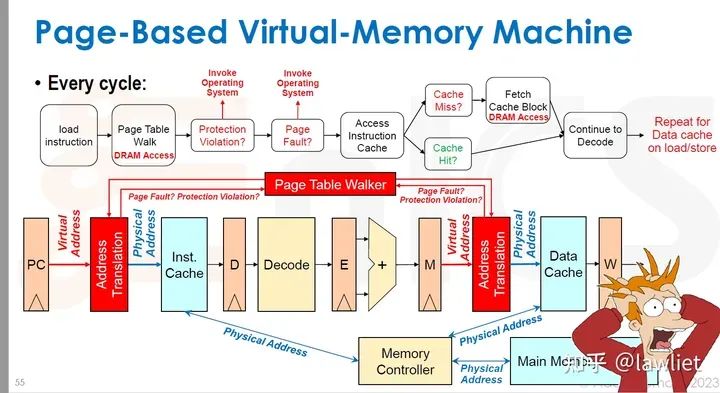
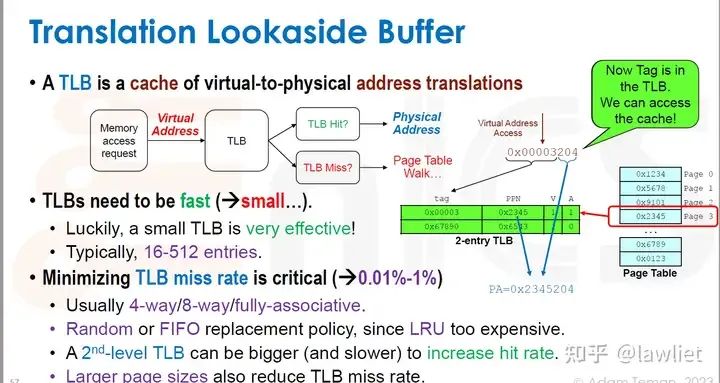
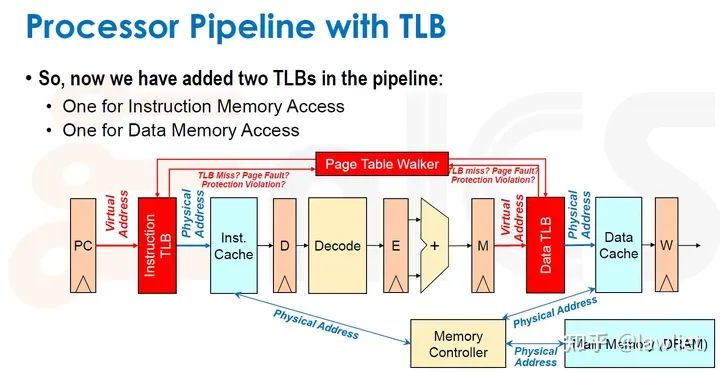
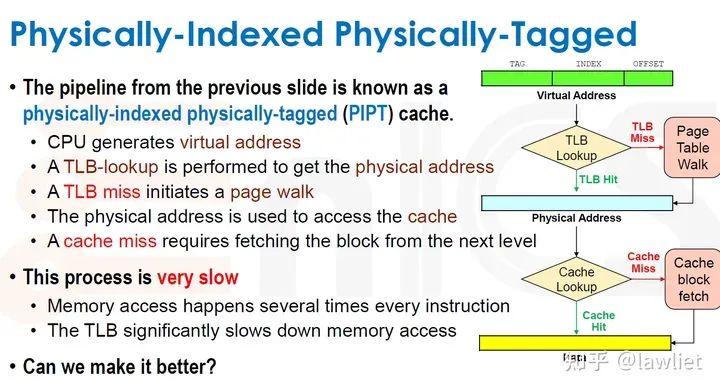
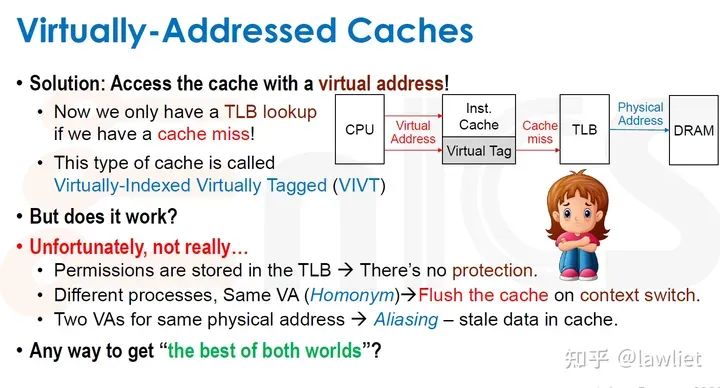
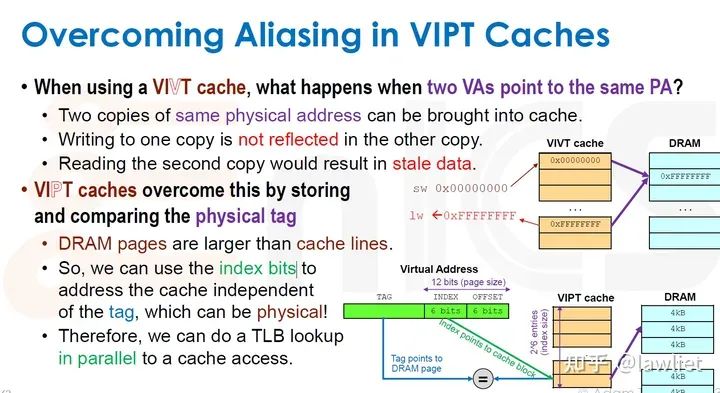
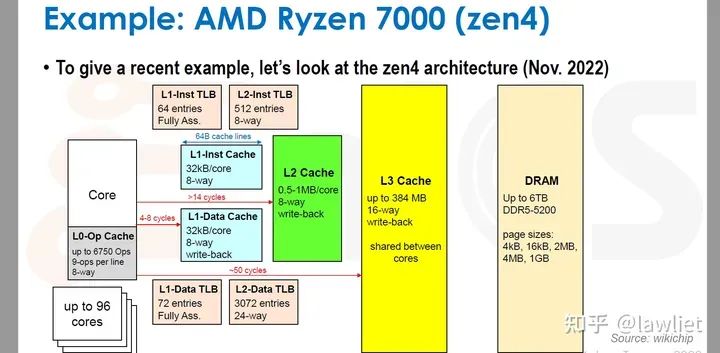
本篇文章将给大家带来Memory相关的内容。我之前的文章写了很多Memory相关的内容,包括Cache、虚拟内存等。感兴趣的可以去看我之前的文章,本篇文章就当是我自己复习这一部分内容了。 本篇文章将基于下面的内容进行展开。其重点基本就是Cache和虚拟内存。 
|


本篇文章将给大家带来Memory相关的内容。我之前的文章写了很多Memory相关的内容,包括Cache、虚拟内存等。感兴趣的可以去看我之前的文章,本篇文章就当是我自己复习这一部分内容了。 本篇文章将基于下面的内容进行展开。其重点基本就是Cache和虚拟内存。
|