 018B10B解决的问题8B10B编码是1983年IBM公司提出的传输编码标准,通常用于高速收发器中,常见的JESD204B、SATA等接口协议,使用查表就可以实现编码和解码。在这些高速收发器的接收端需要通过CDR技术去恢复时钟与数据的相位关系,在这个过程中需要不断的检测数据边沿和数据中心,从而调整时钟和数据的相位,因此需要保证接收的数据需要不断的变化,从而给CDR提供足够多的待检测数据边沿。 另外高速接口电路一般采用交流耦合方式进行连接,在交流耦合电路中的信号线会接电容(隔直通交),如果传输的数据在一段时间内全是1或全是0,那么这段时间传输的信号可以等效成直流信号,会产生直流偏移,在通过电容时,有可能解码错误。 因此通过8B10B编码,保证编码后的数据在一定时间内0的个数与1的个数保持相等。 028B10B编码规则 8B10B就是把8位数据编码成10位数据,8位共有256种状态,而10位数据有1024种状态,可以从1024种状态中选取256种0和1个数相等的数据作为编码结果,在从剩下的数据中选取12个作为控制字符,即常见的K码。 如下图所示,将输入的8位数据分为高3位和低5位,分别进行3B4B、5B6B编码,结果为10位数据。 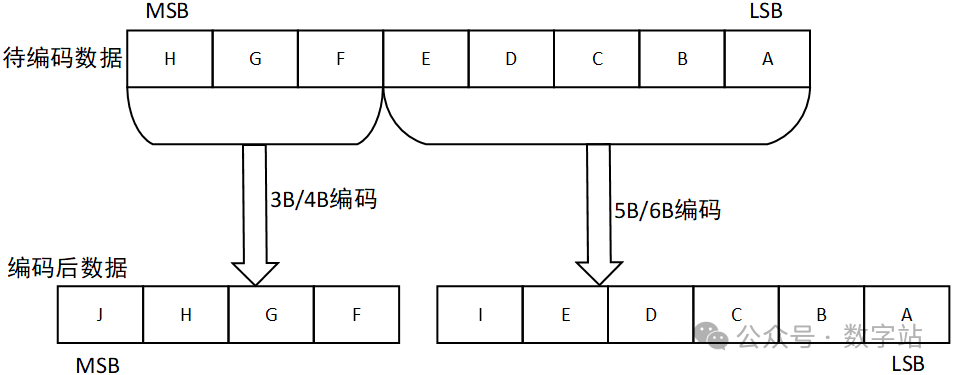 图1 8B10B编码原理 通常把编码前的低5位数据EDCBA的十进制数值记为x,把编码前的高3位数据HGF的十进制数值记为y,原始8位数据可以表示为D.x.y。 比如待编码数据为110_00011,高3位数据的十进制为6,低5位的十进制数据为3,则D.3.6就表示110_00011。 常见的控制字符K.28.5的也是采用上述方式,控制字符的编码结果是固定的,不会与数据的编码结果冲突。 低5位数据总共有32种状态,对应的5B6B编码规则如下表所示。 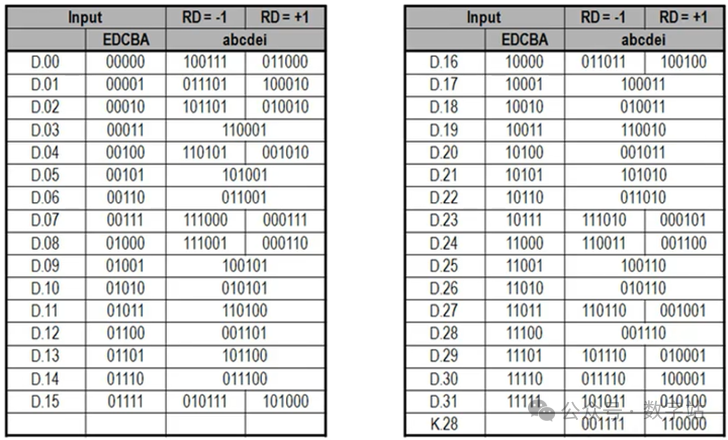 图2 5B6B编码原理 下面是3B4B编码的表格,原理与5B6B编码一致。 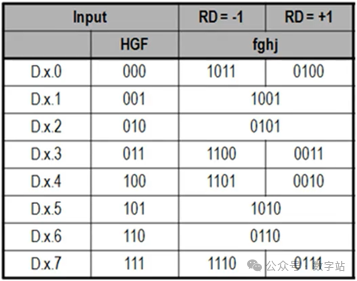 图3 3B4B编码原理 可能第一次看下表会有疑问,为什么D.00的编码结果有两种?RD又是什么东西? 5位数据总共有32种状态,编码结果有6位数据,0和1数量相等的只有000_111、001_011…、110_001、111_000等20种状态。其中000_111和111_000存在三个连续相同的状态,并没有被使用。导致编码后0和1数据相等的结果就只有18种状态,并不能满足输入5位数据的32种数据状态,3B4B编码也有同样的问题。 此时设计编码的人提出,一次编码如果不能保证编码结果0和1个数相等,那么可以让连续两次编码结果的0和1相等,也能满足要求。 极性偏差(running disparity,RD)用来记录上一次编码结果中0和1个数的多少。RD=-1表示编码结果1多于0,RD=1表示编码结果0多于1。 如果编码结果的1和0个数相等,称为平衡编码,此时RD的数值保持不变。如果编码结果1和0个数不等,称为非平衡编码,此时RD的数值翻转,下次编码采用RD对应数值的编码作为编码结果。 将上次8B10B编码结果的RD数值用作本次5B6B编码的起始RD,而3B4B编码的起始RD等于5B6B编码结果的RD,3B4B编码结果的RD作为本次8B10B编码的RD。 对应的编码状态跳转如下图所示。 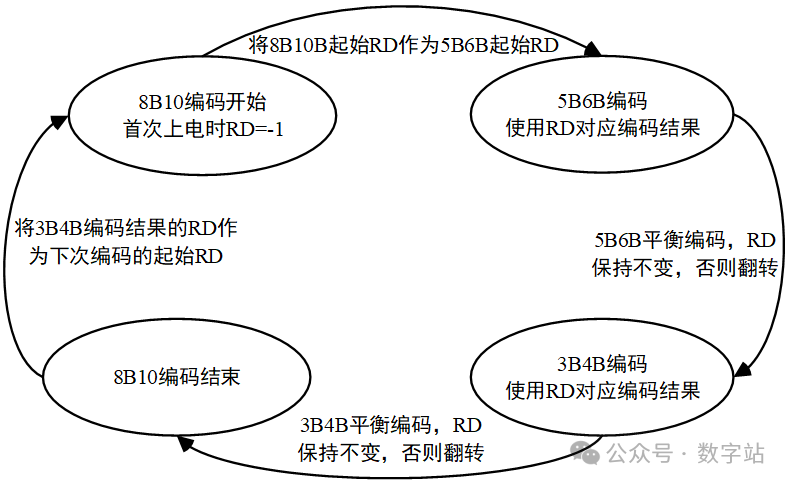 图4 编码状态 通过这种方式才能保证一次编码结果要么0和1个数相等,要么相差两个。关于这方面的讲述,网上绝大多数文章都是错误的,认为上次8B10B编码结果的RD会作为下次5B6B和3B4B编码的起始RD,造成3B4B编码错误。 上述讲解的是数据编码过程,因为8B10B编码大多用于异步串行通信,接收方需要识别数据的帧头、帧尾这些控制信息,从而完成数据的对齐、同步等等。 因此8B10B编码有12个控制字符,通常称为K码,这些控制字符的编码结果是唯一的,不会与数据编码的结果重复。下表就是12个控制字符的编码。 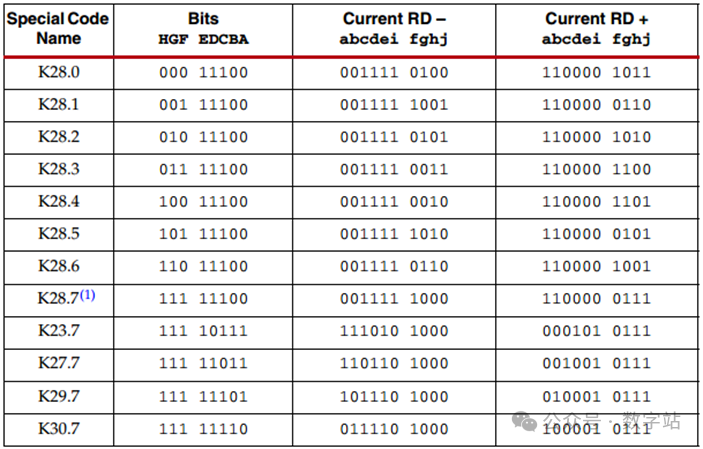 图5 K码的编码规则 因为K码的编码结果是唯一的,因此接收端检测K码的方式很简单,通过一组移位寄存器,将输入数据依次移入,当移位寄存器的数值与K码的编码结果相同时,就认为检测到对应K码了,从而实现对应功能,包括逗号检测、时钟纠正、起始位、停止位等等。 038B10B编码练习 8B10B相关的理论讲解就到此结束了,以两个示例测试是否真的掌握该编码,请问D.8.3的8B10B编码结果是多少? 由于起始RD并没有明确指出,可能为1或者-1,所以会存在两种编码结果。 首先RD=-1时,根据图2得D.8的5B6B编码结果为111001,5B6B编码完成后,RD翻转变为1。将RD=1作为D.x.3的3B4B编码起始RD,根据图3查表得编码结果为0011,再次将RD翻转作为本次8B10B编码结果的RD。 因此起始RD=-1的编码结果为111001_0011,先输出高位数据。 当起始RD=1时,根据图2得D.8的5B6B编码结果为000110,RD翻转作为3B4B起始RD,得D.x.3的3B4B编码结果为1100,因此8B10编码及热锅为000110_1100。 怎么验证上述计算是否正确呢? Xilinx的UG476手册的附录有所有8B10B编码数据的结果,如下图所示,起始RD=-1时,D.8.3编码结果为111001_0011,起始RD=1时,D.8.3编码结果为000110_1100,与上述计算结果保持一致,证明计算方法没有问题。 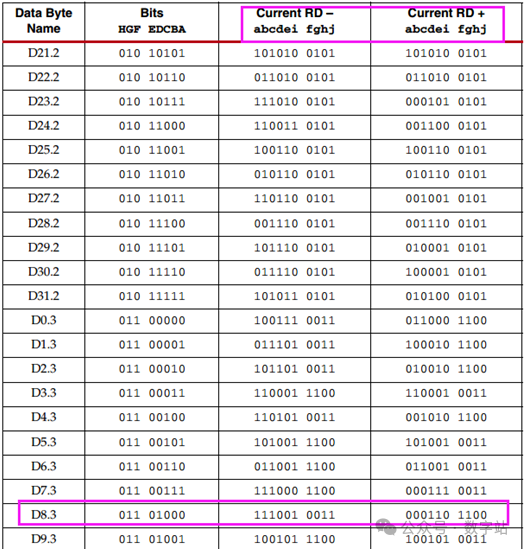 图6 D.8.3的编码结果 第二个问题,当前RD=1,则K.28.5、D.2.6、D.23.4的编码结果依次是多少,且最终的RD是多少? 首先RD=1时,通过图5查得k.28.5编码结果为110000_0101,然后RD保持不变,因为K28.5的5B6B和3B4B都是不平衡编码,因此RD翻转两次的结果就是不变。 因此D.2.6的起始RD=1,首先D.2的5B6B编码结果为010010,RD翻转变为-1。D.x.6的3B4B编码结果为0110,由于D.x.6是平衡编码,因此RD保持不变。 故D.2.6的编码结果为010010_0110,RD最终为-1。 当RD=-1时,D.23.4的5B6B编码结果为111010,然后RD翻转为1。之后D.x.4的编码结果为0010,RD的极性再次翻转为-1。 所以K.28.5、D.2.6、D.23.4的编码结果依次是110000_0101、010010_0110、111010_0010,RD的最终取值为-1。D.2.6、D.23.4的查表结果如下图所示,与上述计算结果保持相同,证明编码规则没有问题。 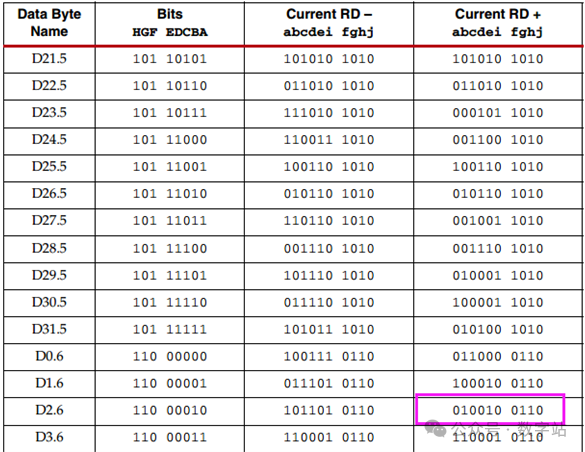 图7 D.2.6的编码结果 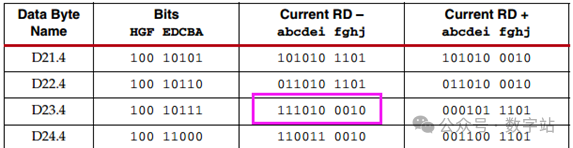 图8 D.23.4的编码结果 从上述编码过程可知,每个输入数据通过查表都可以得到其唯一的编码结果,根据编码结果也可以查表反推进行解码,所以实现这个编码和解码的思路比较简单,直接使用查表法即可。 通过上述编码也可以很清晰知道该编码的缺陷,每次传输的10位数据中有2位是无效数据,损耗比较大。后续的64B66B编码就是为了解决这个问题提出的,但是8B10B编码的误码率会比64B66B编码低。 关于8B10B编码内容讲解就到此结束了,本来最开始是不想写这方面内容的,结果在CSDN和B站看到很多大佬对RD极性变化的理解都有问题,编码结果与官方提供的结果都不相同,因此写了这篇文章,希望对大家的理解有帮助。 |



