 实战系列 #2做芯片测试这么多年,我犯过的错比做过的项目还多。这篇文章不讲高大上的理论,就说三个让我半夜被叫醒、被老板骂、被客户索赔的真实翻车故事。每个坑背后都是一条用真金白银换回来的测试铁律。 �� 太长不看 ✦坑1:电源针间歇性接触不良,良率掉5个点,花了三天才发现——最难的bug是时好时坏的bug ✦坑2:Guardband设太紧,良率从92%崩到78%,差点停产——你设的不是余量,是乘法叠加的死刑判决 ✦坑3:OTP trim少烧了5个cycle,3000颗在客户SLT退货——程序中的问题烧进芯片带出厂了 ✦核心教训:先查硬件再看代码;理解统计叠加效应;OTP烧写值必须双人复核+自动回读 上篇文章结尾我说了句"下一期聊聊踩过最深的3个坑"——没想到后台催更的私信把我都炸懵了。好吧,今天不整那些虚的,把这三段血泪史摊开给你看。 先交代一下背景:我十几年前入行的时候跟绝大多数人一样,觉得自己测试技术牛得不行,什么ATE机台、什么向量文件、什么良率分析——学学就会了。直到被现实狠狠地教育了三次,才明白"测试"这两个字的真正分量。 坑1:电源Pin间歇性接触不良——三天找不到原因,最后是一张Shmoo救的命那是入行头几年的事。一个新项目导入,CP测试良率一直在82%~84%晃悠。隔壁老王的同款产品稳定在88%~90%,凭什么我就低5个点? 我第一反应:程序有问题。 接下来三天干了什么? · 把测试向量重写了三遍——没用 · 把Timing参数调了又调——良率纹丝不动 · 把Guardband从±10%缩到±5%又扩回±10%——该多少还是多少 · 打电话问DFT:"你插的scan chain是不是有问题?"——DFT工程师差点顺着网线过来打我 第三天晚上九点,我瘫在机台前面,盯着Shmoo Plot发呆——等等,这个Shmoo不对劲。 Shmoo是啥?简单说就是把电压从低到高、频率从慢到快跑一遍,PASS的格子涂绿色,FAIL的涂红色。正常的Shmoo图应该是左上角一大片绿(低压低频肯定过),右下角一大片红(高压高频肯定挂),中间一条过渡带。 但我看到的Shmoo是这样的:大部分区域是绿的,但有个别的点随机性地冒红色。不是一条边界,是孤立的小红点——就好像有人不小心把红墨水甩到绿背景上。 这是间歇性故障的典型特征。 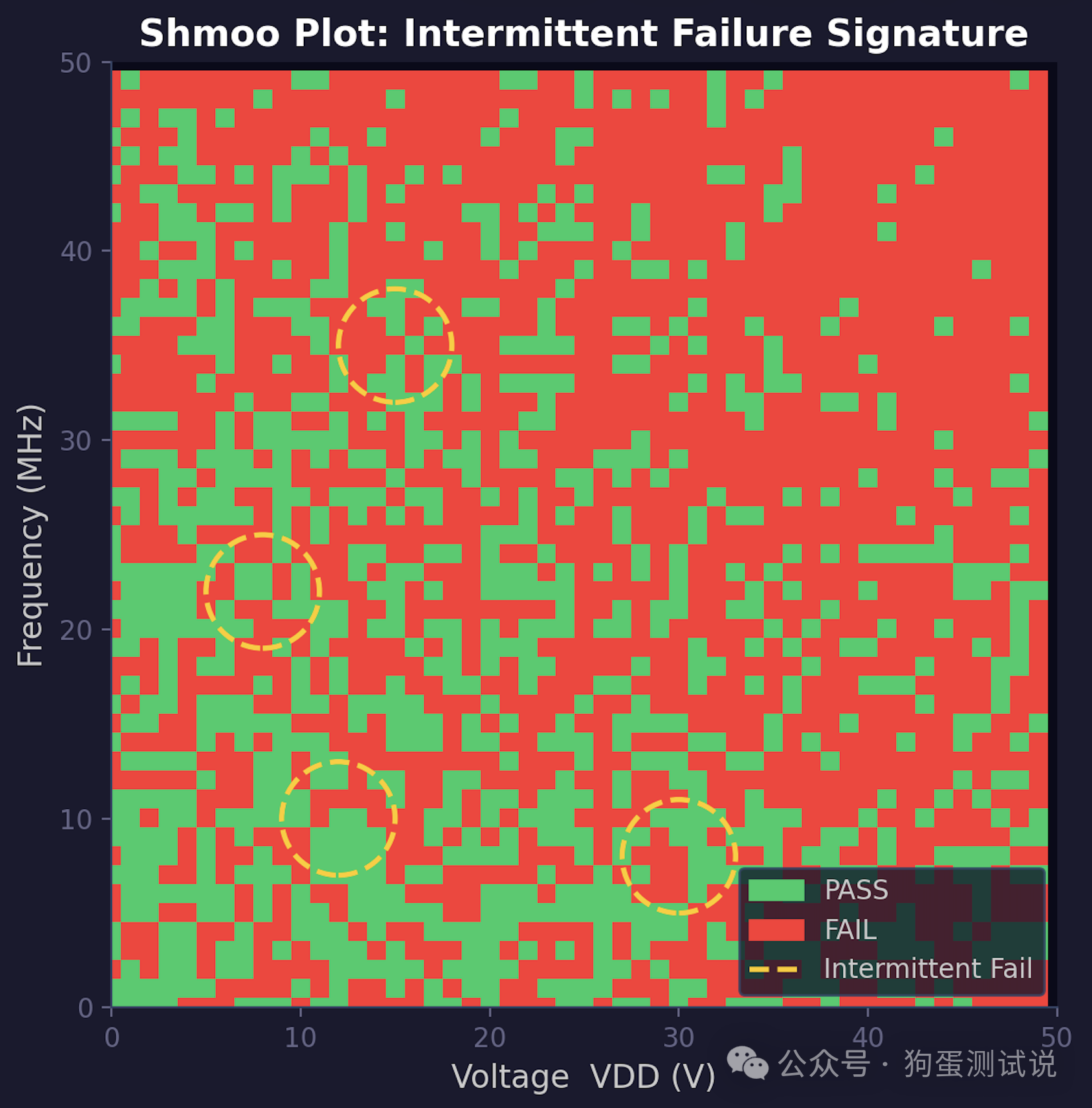 图:Shmoo Plot中绿色的PASS区域里随机散布孤立红色FAIL点——正常的过渡区是一条斜线,而不是散点。出现这种"红墨水甩到绿布上"的图案,基本可以锁定间歇性故障。 我顺着这条线索查下去——把Shmoo缩小到某一条具体的电源Pin,跑了一遍接触电阻监控。结果出来了: 这颗Pin的接触电阻,80%的时候是180 mΩ(完全正常),20%的时候跳到了800 mΩ。而且跳跃毫无规律——不是每颗Die都高,不是每步动作都高,就是随机发作。OS测试那几毫秒它刚好是好的,所以OS全PASS。但等到跑功能测试的时候,大电流一抽(几百毫安级别),根据欧姆定律 V = I × R,800 mΩ 的接触电阻上产生的动态压降(IR Drop)瞬间把芯片内部的 VDD 拉到了正常工作电压以下——Die就复位或跑飞了。不是接触电阻本身暴增,而是固定的大电阻 × 大电流 = 电压坍缩。 最后发现是探针卡上这根针的针尖有点脏,上面粘了一小颗前一批晶圆的硅碎屑。碎屑有时候被压扁了接触就还行,有时候侧翻了接触就崩了。 �� 狗蛋说:"OS全PASS不等于接触没毛病。间歇性接触不良是产线最恶心的bug——没有之一。它只在最关键的瞬间发作,等你回头查的时候又装得人模狗样。对付它的唯一办法:接触电阻监控+Shmoo+趋势分析,三件套缺一不可。" 这条血泪教训值多少钱?这三天产线停着等结论,按每小时5000美元的停机成本算——将近40万美元。加上浪费的晶圆和人力,半百万级别。 从那以后我定了条规矩:每个新项目导入,跑Fun Test之前必须先跑全Pin接触电阻扫描(四线法),低于同批次历史均值3σ才放行。接触电阻本身不做Shmoo——它是定值测量——但电源Pin的良率趋势分析(Trend Analysis / Distribution Mapping)要跑。当某根Pin的接触电阻分布出现长尾,或者均值出现漂移,就是该清洁探针卡了。 坑2:Guardband设太紧,良率从92%崩到78%,产线差点停产踩第一个坑的时候我学乖了——"得留余量,得加Guardband"。然后矫枉过正,直接翻了第二个坑。 入行第三年,我负责一个高速ADC芯片的FT测试。Datasheet上的AC Timing规格是: · Setup Time: 2.0 ns min · Hold Time: 1.5 ns min · Clock-to-Output: 5.0 ns max 我心想,留点余量稳妥——于是在测试程序里写了: · Setup Time Limit: 2.5 ns min(加了0.5 ns Guardband) · Hold Time Limit: 2.0 ns min(加了0.5 ns) · Clock-to-Output Limit: 4.5 ns max(减了0.5 ns) 还不止——所有DC参数也加了Guardband: · VOH: 从2.4V min 改到 2.5V min · VOL: 从0.4V max 改到 0.3V max · 静态电流IDDQ: 从10 μA max 改到 5 μA max 然后开跑。 良率跳水——从92%直接干到了78%。 我当时疯了。"不可能啊,我明明是在帮品质把关,怎么良率崩了?" 后来被一个老工程师拉去小黑板前上了一课。他写了一个公式给我看: 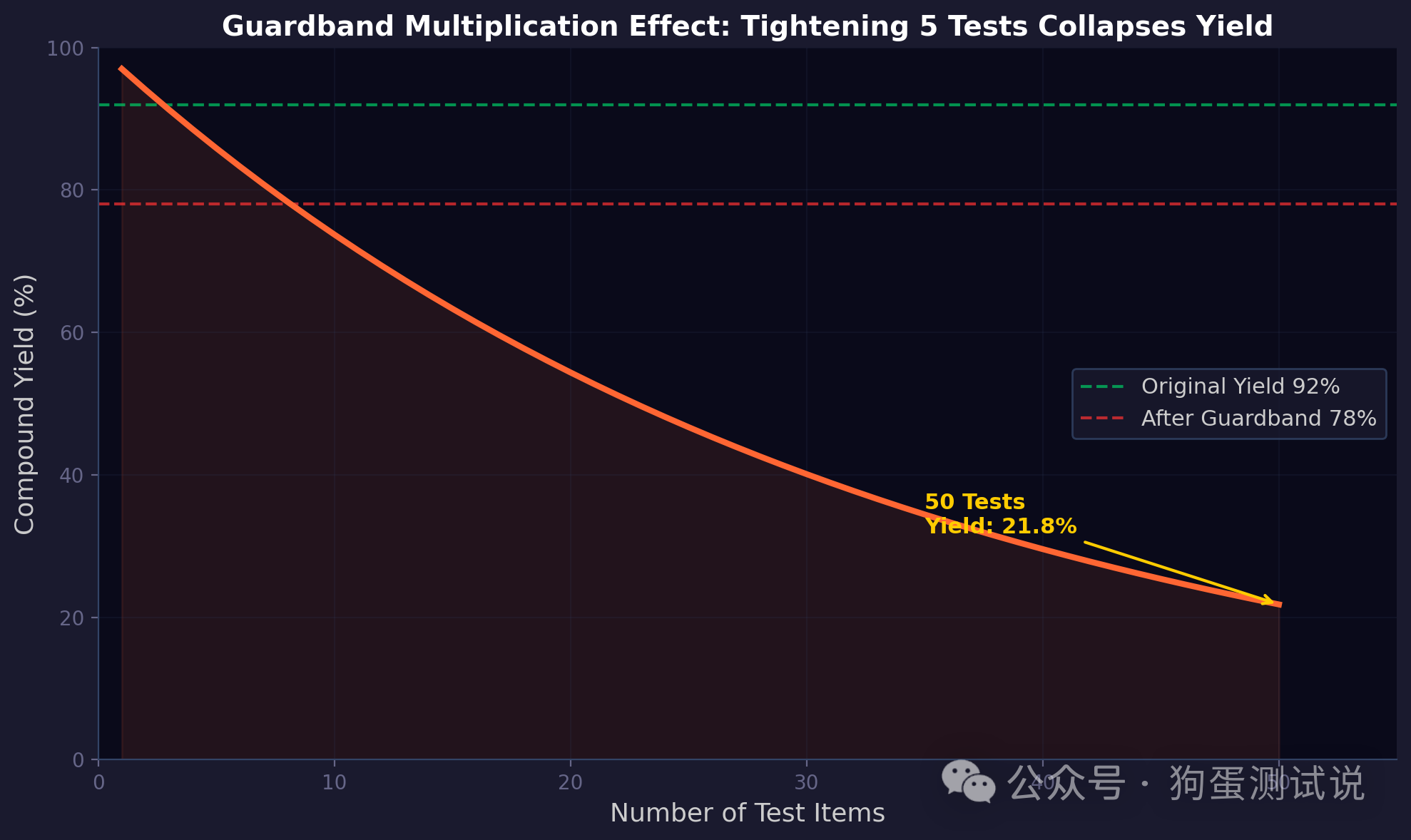 图:假设单项PASS概率97%,随着测试项数量增加,复合良率呈指数级下降。50项测试时,即使每一项看似只缩了2~3个百分点,复合起来良率从92%崩溃到78%以下。 假设一个芯片有50项测试,每项测试的PASS概率是P。 如果所有测试独立,总良率 Y = P⁵⁰。 我说这我懂。他说那你算算——你的 Guardband 让这 5 项测试的 PASS 概率从 99.99% 降到 97% 甚至 90%,如果 50 项全部如此,良率是多少? 0.97⁵⁰ ≈ 21.8%。 我后背一凉。 他接着说:但你别慌——以上是假设所有测试项相互独立的极端情况。实际上,ADC 的 Setup Time、Hold Time、Clock-to-Output、IDDQ、VOH/VOL 在工艺角上是高度正相关的。工艺跑 Fast Corner,时序参数一起变快,电流也一起变大;跑 Slow Corner 则反之。因为相关性,复合良率不至于崩到 21.8%——但依然会跌得很惨。 再算笔细账:我设的那些Guardband,每一个单项的PASS概率大概是这样: · Setup Time +0.5 ns: 99.7% → 97%(实际分布边缘有尾巴) · Hold Time +0.5 ns: 99.7% → 97% · VOH +0.1V: 99.5% → 96% · IDDQ砍一半: 99% → 88%(这个最狠,IDDQ本身就是小尾巴分布) IDDQ那项最致命——5 μA的限值把一大批正常芯片的Die-to-Die工艺波动也判了死刑。不同晶圆、不同批次的IDDQ均值漂移1~2 μA是完全正常的。我那个5 μA的限值等于把正常工艺波动也当成故障了。
复合良率 = 0.97 × 0.97 × 0.96 × 0.96 × 0.90 × (其他45项平均99.99%) ≈ 78%——跟实际完全吻合。 �� 狗蛋说:"Guardband是一个乘法游戏。单项缩1%,50项缩完就是40%的良率损失。Guardband必须基于实测分布(Datalog)来设,不能拍脑袋。拍脑袋的后果就是——你用100%的努力,干掉了92%的良率,只挽回了0.1%的缺陷漏出。不是一个划算的买卖。" 后来怎么做的? · 先跑5000颗Die的Datalog,画出每一项的实测分布 · Guardband只设在分布的自然尾巴上(mean ± 6σ),而不是拍脑袋 · IDDQ改用Delta-IDDQ(每颗Die跟自己比,而非统一阈值) · 把50项Guardband缩到只有5项关键参数加Guardband · 良率从78%回升到90% 这条血泪教训值多少钱?两周低良率产出加上人工排查和重新校准的时间,综合损失约 10万美元。 坑3:OTP trim少烧了5个cycle,客户退回来3000颗这个坑是最大的。因为它涉及的不是良率高低,而是质量事故。入行第四年,一个SoC项目在FT测试阶段。一切顺利——良率稳定在88%,Datalog看起来干干净净,Spec review过了三遍。Release。 三个月后,客户传真过来了——不对,现在是邮件了——一封标题带"URGENT"的邮件:你们供的批次A,在客户系统级测试(SLT)中失效率达到3.1%。 3000颗失效。 我整个人是懵的。FT良率88%,SLT翻出来3%——这意味着我们把有缺陷的芯片当Good Ship出去了。Underkill。 第一反应又是"是不是客户系统有问题?"——但人家把失效分析的报告一起发过来了,示波器截图、逻辑分析仪波形、定位到了具体模块。 我把退回来的芯片上ATE重新跑了一遍。猜怎么着? FT全PASS。 这就不是一个良率问题——是测试程序自身有盲区。某种缺陷只在真实系统的工作条件下才会暴露,ATE上测不出来。 我开始逐行检查测试程序。 查了三天,找到了。但问题不是某条 wait指令——而是一行 OTP烧写代码。 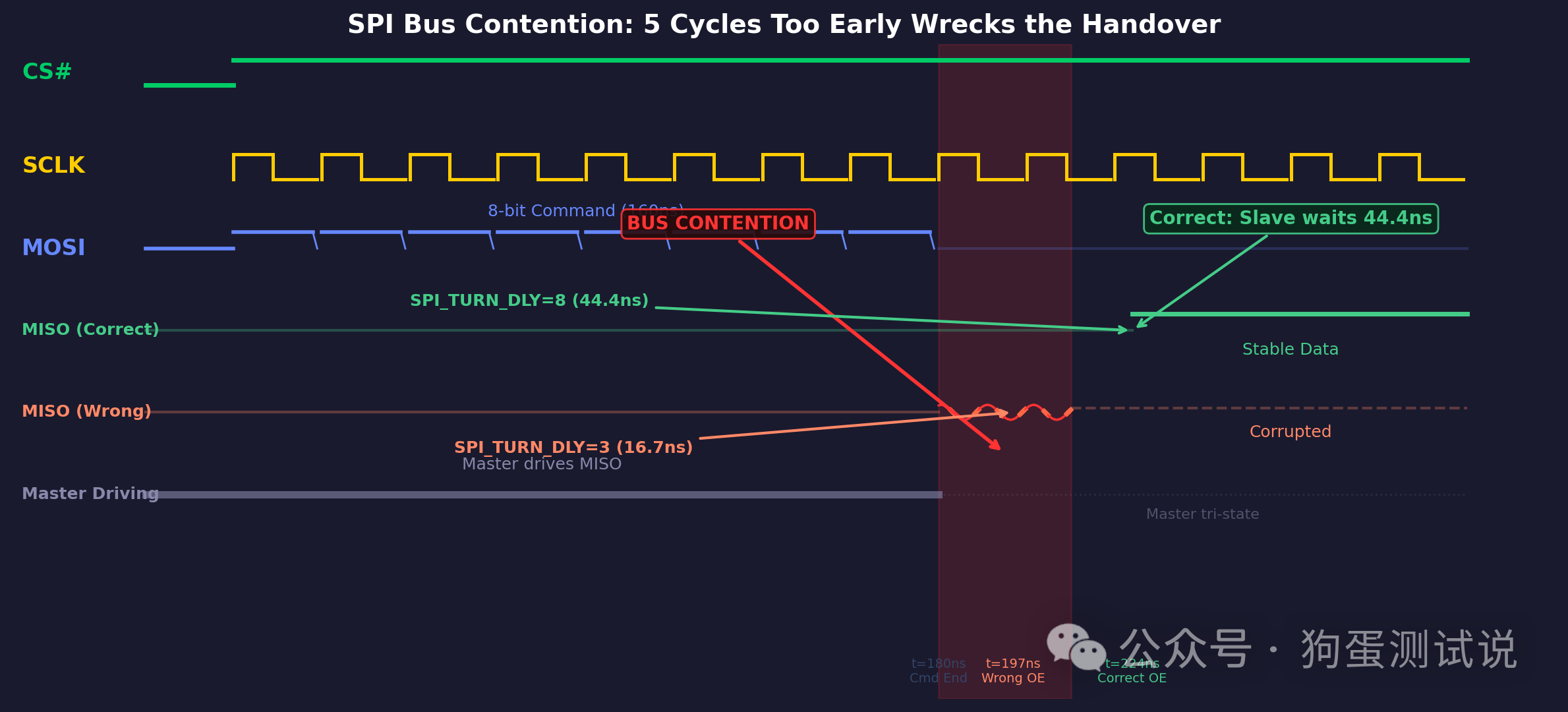 图:芯片SPI接口的 MISO 驱动时序。SPI_TURN_DLY控制从命令接收完成到MISO输出使能之间的核心时钟周期数。OTP中烧入的值直接决定了这个延时。 这颗SoC的SPI从机模块里有一个固件可配的寄存器,叫 SPI_TURN_DLY。它控制芯片在收到SPI读命令后、驱动MISO数据之前插入多少个内部核心时钟周期的延时。 简单说——SPI_TURN_DLY的值决定了一颗芯片在SPI总线上"多快回应"主设备。这个值通过FT测试流程中的 JTAG访问写入芯片的OTP(一次可编程存储单元),出厂后芯片启动时固件从OTP读出这个值来初始化SPI模块。 所以: ATE上设的 SPI_TURN_DLY→ 烧进OTP → 芯片出厂带着走 → 到了客户SLT里还是这个值。 那到底哪里出了问题? FT测试的OTP烧写序列里有一行,本应写 SPI_TURN_DLY = 8(8个核心周期),但实际写了 0x03(3个核心周期)。 这少了的5个周期(核心时钟180 MHz,每个周期≈5.56 ns,5个周期≈27.8 ns)就是全部问题的根源——不是「数据来得太慢来不及采样」,恰恰相反,是数据来得太快,bus contention了。
SPI 是同步总线,数据来得早不等于更好。这里的问题是这个: 标准 SPI 读操作中,主设备(ATE 或客户 MCU)驱动 MISO 信号线直到发送完最后一个 command bit,然后释放总线(三态)。从设备等一段时间后接管 MISO,开始驱动 response data。 SPI_TURN_DLY控制的就是这个「从三态切换到驱动」的等待时间。 正常值 8 个周期:主设备有充足时间完成最后一个 SCK 边沿并释放 MISO 总线 → 从设备干干净净地接管 → 数据稳定。 错误值 3 个周期:从设备提前 5 个 cycle就开始驱动 MISO。这时主设备的输出级可能还没完全释放,两端同时驱动 MISO 这根线——Bus Contention(总线冲突)。MISO 上的信号被两边同时拉,波形出现中间态、毛刺、不完整跳变,接收端采样到的数据就错了。 那为什么这个错误能在FT里PASS? 原因一:ATE 的电气环境好,Contention 被掩盖了。 ATE 的 PCB 走线极短(<2 cm),负载电容小,数字通道驱动能力强。即使两端同时驱动,信号在短距离内仍然能快速 settle 到正确电平。加上 ATE 的采样窗口宽(wait 150给了充足的采样余量),即使在 contention 期间波形有毛刺,采样时刻已经过了混乱期,读到的数据仍然是对的。所以 FT 怎么跑怎么 PASS。 原因二:客户 SLT 的电气环境差,Contention 暴露了。 客户系统的 SPI 走线长 5~10 cm,负载电容大,温度高达 85°C。Bus Contention 导致的波形畸变在短走线小负载下不致命,但在长走线大负载下就严重了: · 两端同时驱动 → MISO 上的电压被拉到一个不确定的中间值(不完全高也不完全低) · 85°C 下输出晶体管的驱动能力下降 → 信号从中间态恢复的时间更长 · PCB 走线长 → MISO 与 SCK 之间产生 skew → 采样时刻正好撞在 contention 造成的混乱窗口上 3.1% 的 SLT 失效,正是这批芯片在 3-cycle 提前驱动下、在客户 PCB 环境中发生了不同程度的 bus contention,导致 MISO 数据被破坏。 为什么改成200 ns就解决了? 不是ATE自己多等50 ns救的——而是 把OTP烧写值修正确了: SPI_TURN_DLY = 0x03(3) → 0x08(8) 改了之后,芯片出厂时带着44.4 ns的内部延时,无论在ATE还是SLT环境里都有充足的时序余量。重新跑了1000颗退回来的芯片,全部PASS。 良率没变——因为正常的芯片就算 SPI_TURN_DLY = 3,在ATE的宽窗口里也照样能过。影响只在SLT那端。 �� 狗蛋说:"很多人以为ATE上的 wait指令只影响ATE自己采样,别人家的芯片根本不认。但如果这个 wait背后关联着一条OTP烧写——你改的不是ATE程序,是芯片出厂时的固件配置。一根OTP bit的错误,等芯片走到客户SLT才暴露出来。从发现到定位花了三天,真正的原因在一行代码里藏了三个月。测试程序不是你在机器前写的那几行pattern——是你写进芯片里带出厂的所有东西。" 那这次事故后我做了什么? · 每条时序路径都跑Shmoo——不光跑VDD vs Frequency,还跑Setup Time vs Hold Time的二维Shmoo。双向的Shmoo才能暴露那种"我觉得够了但其实不够"的死角 · 所有wait/timing参数必须留≥20%余量——从实测边界往回退至少20% · OTP烧写值双人复核+自动校验——OTP烧写序列的每个trim值在写入前必须有2人签名,写入后自动回读比对。一根OTP bit的错误,三个月后才暴露=40万美元 · FT release前做SLT对比验证——至少取500颗在SLT上跑,确认FT的Bin1(Good)和SLT的Pass之间有≥99.5%的一致性 · 引入"测试覆盖率"追踪——不只是DFT的覆盖率(Fault Coverage),而是功能测试级的Coverage Matrix 这条血泪教训值多少钱? · 客户退货3000颗,按每颗$15计算 = $45,000的直接损失 · 客户信任损失 + 重新Qualification费用 ≈ $200,000 · 后续三个月的批量加测(100% SLT)≈ $150,000 · 合计将近40万美元。 而且——客户那边采购总监说了一句话我到现在还记得:"你要是再出一次这种问题,你们就是第二供应商了。" 三条铁律——花了100万美元买来的写到这儿,把三个坑放在一起复盘,你会发现它们有一个共同的根:
这三条铁律,估值大约一百万美元——就是这三个坑的直接经济损失之和。 我不是在跟你开玩笑。做芯片测试的头五年,我犯的错比做的项目还多。每一条铁律都是真金白银砸出来的。你现在读到的不是"最佳实践",是"最贵学费换来的教训"。 如果你刚入行或者还在学校,希望你把这三条刻在脑子里。等你以后在产线上半夜被叫醒的时候——先把Shmoo拉出来看一眼,再碰程序。 |



