 我们(指代本文作者Dylan Patel)最近参加了在旧金山举行的第68届年度 IEEE 国际电子设备会议。IEDM 是最先进的半导体器件技术的首屈一指的会议。在本届会议上,包括英特尔、台积电、三星、IBM、美光、欣兴、日月光、应用材料等无数企业,IMEC、CEA-Leti等研究机构,再到多所大学在内的组织都展示了半导体的前沿技术。这里的前沿不仅仅指最先进的逻辑工艺,还包括存储器、模拟、封装等诸多领域。保持对本次会议的关注很重要,因为它展示的技术将导致设备、代工厂、无晶圆厂、设备和封装等业务发生变化。本文是关于 IEDM 上讨论的许多进步、发展和研究的简短系列的一部分,其中将涵盖高级逻辑技术和高级封装。本文将涵盖 CFET——GAA晶体管的下一个演进、顺序堆叠(Sequential Stacking)、LFET、应用材料无障碍钨金属堆叠(Barrierless Tungsten Metal Stack,)、三星混合键合逻辑 4um 和 HBM、ASE FoCoS、台积电 3nm FinFlex 和自对准触点、英特尔 EMIB 3 和 Foveros Direct、Qualcomm Samsung 5nm DTCO & Yield、IBM 垂直传输 FET (VTFET) 和 RU 互连等技术。 台积电 FinFlex 在 IEDM 2022 上,台积电谈到了 N3B 和 N3E 。在关于N3E的论文中,台积电介绍了FinFlex。这是进入 N3 节点系列的巨大设计技术协同优化 (DTCO) 的一部分。FinFlex 是一种高级形式的鳍减少( fin depopulation)。通常,随着鳍的减少,标准单元中 NMOS 和 PMOS 鳍的数量会减少。这允许降低电池高度,从而提高密度。有了更先进的节点,每个鳍片还可以承载更多的驱动电流,允许鳍片数量减少而对性能的影响很小。 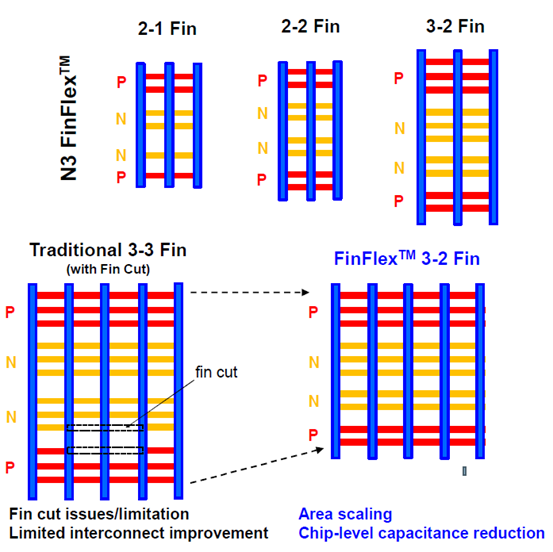 然而,随着单元(cell)高度的降低,互连成为一个更具限制性的因素。对于1-fin cell,几乎没有互连空间,互连几乎肯定会成为唯一的瓶颈。对于 FinFlex,使用 2-1 fin 设置,其中 1 fin cell堆叠在 2 fin cell的顶部。这有助于缓解互连瓶颈并有效地产生高度为 1.5 fins的cell。借助 N3E,台积电提供了三个库,一个用于高密度的 2-1 单元库,一个用于平衡功率和性能的 2-2 单元库,以及一个用于高性能的 3-2 单元库。 据台积电称,2-1 单元库( cell library)在相同性能下功耗降低 30%,在相同功率下性能提高 11%,并且相对于其 N5 节点上的 2-fin 库面积减少 36%。2-2 单元库在 iso-performance 下功耗降低 22%,iso-power 性能提高 23%,面积减少 28%。3-2 单元库提供低 12% 的功耗 iso-performance、高 32% 的性能 iso-power 和 15% 的面积。 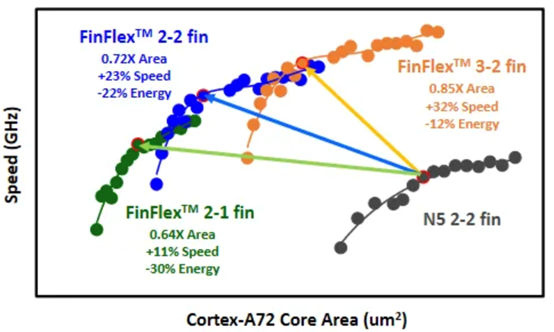 N3E 还提供 6 种阈值电压(threshold voltage )选项,eLVT、uLVT、uL-LVT、LVT、L-LVT 和 SVT。每一种都在功率和性能方面进行了不同的权衡,并允许设计人员更精确地调整它们的功率性能特性。 比较 2-1 和 3-2 cell时,台积电显示 3-2 cell的性能高出 9%。除非设计人员绝对需要这种性能,否则性能上的提升是微乎其微的。这加强了更密集、更节能的图书馆的理由。但是,这忽略了互连密度限制。FinFlex 使设计人员能够使用密度较低的单元(例如 2-2 和 3-2 单元)实现最高密度,以最大限度地提高互连布线和性能。 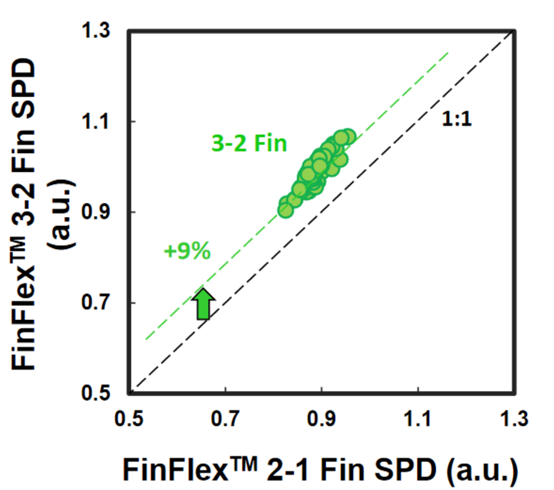 N3E 的金属堆叠虽然比 N3B 略微放松,但仍然非常致密。metal 0 的间距为 23nm,比 N5 减少了 18%。metal 0还提供双倍宽度,以实现更低的电阻和更高的性能。  台积电在铜互连中加入了创新的liner,以降低较低金属层的电阻。我们相信这种liner是钌,英特尔也在其 10nm 节点中用作liner。接触电阻降低了 20-30%,通孔电阻降低了 60%。台积电还提到,在 N3B 上需要使用 EUV 进行双图案化的三个关键层已被在 N3E 上使用 EUV 进行单图案化所取代。这降低了复杂性、成本并缩短了周期时间。 N3E 在今年晚些时候进入大批量生产时,将成为生产中最先进的节点。台积电将继续在逻辑前沿占据主导地位。像 FinFlex 这样的创新表明台积电正在锐意进取。 TSMC 3nm 自对准触点 (Self-Aligned Contacts N3B) 自从台积电在 N16 上过渡到 FinFET 以来,鳍的轮廓对于提高性能和降低功耗至关重要。尽管台积电能够将栅极长度从 N7 上的 16-23nm 减少到 N3B 上的 12-14nm,但台积电也提到栅极长度缩放已达到极限。即使采用鳍片优化,台积电也无法进一步降低这一点。这进一步强调了设计技术协同优化 (DTCO) 对于进一步扩展到未来的重要性。此外,有人提到 FinFET 晶体管架构已达到极限,必须转向纳米片晶体管架构。 通过 N3B,台积电还实施了自对准触点 (SAC:Self-Aligned Contacts)。这非常有趣,因为英特尔从 22nm 开始就开始实施 SAC。同时,台积电第一个采用该技术的节点是N3B。此外,他们还删除了 N3E 中的 SAC。 由于接触多晶硅间距和栅极长度之间的比例差异,接触的着陆面积已显着缩小。更严格的对齐公差和由多个掩模引起的重叠问题加剧了这种情况。 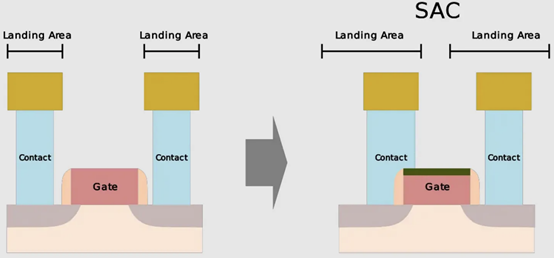 SAC 使触点甚至可以落在栅极顶部而不会使晶体管短路。虽然这增加了工艺复杂性并因此增加了成本,但它提高了良率。不幸的是,随着gate-SD接触电容显着增加,它也会影响性能。 台积电在 N3B 上的方案允许栅极接触结处的泄漏保持恒定,即使在更宽的栅极长度和工艺变化(其中接触和栅极与栅极的不同部分对齐)也是如此。SAC 还将接触电阻降低了 45%,将变化降低了 50%。这允许更好的静电和性能,以及更高的制造产量。 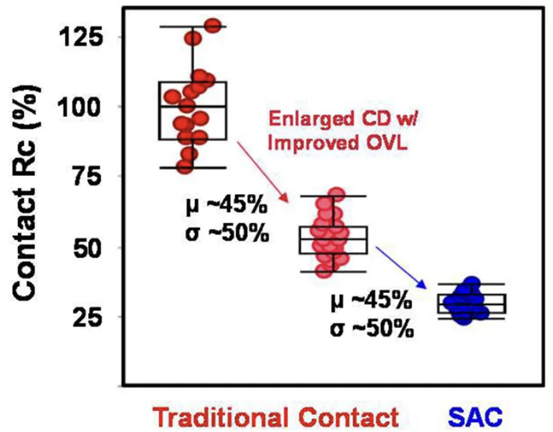 随着栅极和接触之间的间隙不断减小以及由于 FinFET 结构,台积电面临着增加栅极接触结处电容的问题。虽然较厚的垫片可以缓解这个问题,但这会带来其他问题,例如更高的接触电阻。不可避免地,台积电希望降低介电常数并使用低 k 材料。尽管空气的 k=1 很有前途,但台积电的 TCAD 模拟表明,与切换到 k<4.0 的电介质相比,它的影响更小。这将最大电压提高了 200mV 以上,并将结点处的电容降低了 2.5%。这些只是优化新工艺技术时可能被忽视的一些次要细节。 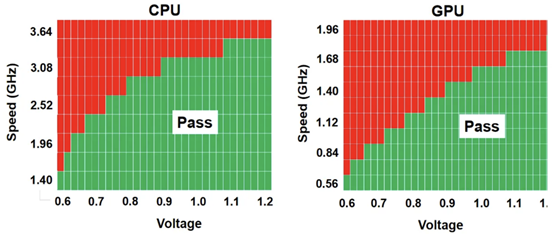 台积电还在其 N3B 节点上展示了测试芯片的 shmoo 图,其中显示 CPU 核心在 1.2V 时达到 3.5 GHz,GPU 核心在 1.2V 时达到 1.7 GHz。他们还展示了芯片中 SRAM 的 shmoo 图,该芯片在低至 0.5V 时仍能正常工作。  高通和三星 DTCO 在IEDM上,高通和三星还谈到了三星5LPE节点上搭载骁龙888的DTCO。高通表示,最小的鳍间距 (FP)、CGP、金属间距和 SRAM 位单元用于实现比 7LPP 缩小 25%。这些变化可以在 5LPE 的 Ultra High-Density 库中看到。然而,这些收缩也伴随着工艺风险的增加。 从开始到初始生产,三星减少了 60% 的缺陷,并通过大批量制造进一步将其减少到基准的 2%。5LPE 也经历了出色的产量提高,比 10LPE 和 7LPP 更快。部分原因还在于 5LPE 是对 7LPP 的增量改进。 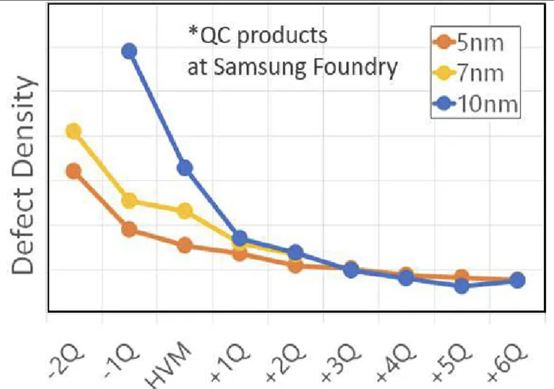 高通和三星还与 DTCO 合作大幅提高良率,将低电压操作的良率损失降低 2.5 倍,这是移动 SoC 的主要用例。他们还将有缺陷的设备数量减少了 9 倍,这非常重要。  通过持续的 DTCO,高通和三星还将 CPU 功耗降低了 7%,总功耗降低了 3%。随着工艺节点缩放速度变慢,DTCO 对于实现芯片的理想特性将变得越来越重要。  三星还将他们的第一代节点 5LPE 与他们的第二代节点 5LPP 进行了比较。他们表明,它在相同功率下实现了 5% 的更高性能。5LPP 也用于 Snapdragon 8 Gen 1,以 4LPX 的名义销售。  先进的逻辑技术:晶体管架构 在 Gate All-Around FET (GAAFET) 和 Forksheets 之后,该行业可能会转向互补 FET (CFET),其中 NMOS 纳米片堆叠在 PMOS 纳米片之上,反之亦然。这是一个困难的过程,因为 P 型和 N 型的形成需要非常高温的外延生长。无论您制作第 2 个,都会导致第 1 个暴露在高温下,这可能会破坏它。台积电、英特尔、IMEC都对此进行了研究。为了制造 CFET,有两种方法,sequential 和 monolithic.。 一、通过直接晶圆键合与 Ge Nanosheet p-FET 组成的的异质 3D Sequential CFET 韩国高等科学技术研究院提出了一种Sequential CFET 制造方法。KAIST 通过采用顺序堆叠方法解决了温度问题,在这种方法中,他们执行高温外延生长,然后通过晶圆间键合将它们单独组合在一起。底部 pFET 由 Ge 组成,而顶部 nFET 由 Si 组成。  这种新方法允许具有更高电子迁移率的 Ge 晶格更优选的取向。在最近的前沿节点中,pFET 的驱动电流问题尤其严重,这是缓解该问题的一种方法。经过测试,添加顶部 nFET 的过程不会影响底部 pFET 的电气特性。  二、通过 CVD 外延生长的单片 3D 自对准 GeSi 沟道和共栅极互补 FET 国立台湾大学展示了他们在单片 CFET IE 方面的工作,无需晶圆键合。这可以通过低温(400C)外延生长来实现,这将防止先前制造的结构被破坏。他们用 75% Ge 和 25% Si 制造了 SiGe 沟道,并使用 P/N 结隔离 CFET 的两半。通过他们的方法,他们能够成功地将两个 pFET 通道堆叠在 1 个 nFET 通道之上。  虽然之前已经展示了堆叠式 nFET 上的堆叠式 pFET,但这是第一次展示带有 P/N 结的 pFET,而且该工艺似乎对源极和漏极的形成影响很小。他们声称这比以前的方法更容易实施。  三、IBM 垂直传输纳米片 与业内其他公司不同,IBM 寻求一种不同的方法,采用不同的晶体管架构,一种使用垂直纳米片。这种架构被称为垂直传输 FET (VTFET)。  这种方法的一个优点是它允许 CGP 微缩得更多。使用常规晶体管架构将 CGP 扩展到 40nm 以上将被证明是极其困难的,并且可能会在电阻和电容方面进行过多的权衡。IBM 之前曾在 2021 年的 IEDM 上展示过 VTFET。 这次他们展示了 CGP 为 40nm 的 VTFET,使用双扩散中断。他们还表示,零扩散中断设计是可能的。尽管 IBM 能够制造此类 VTFET,但他们发现电容比模拟高 20%,驱动电流低于预期,最佳芯片为目标的 90%。  IBM 通过转向这种架构展示了与垂直纳米线相比令人印象深刻的性能改进。 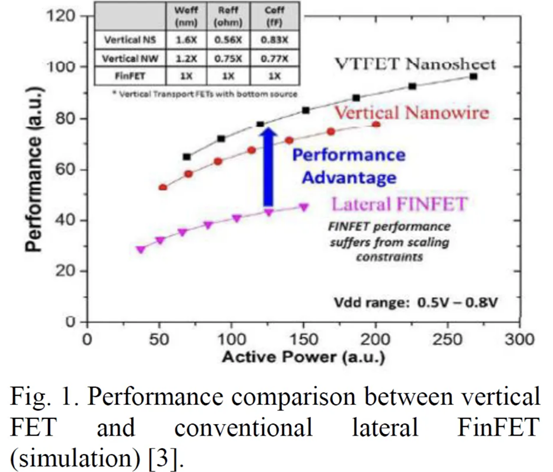 四、用于埃技术节点的异构 L 形场效应晶体管 (LFET) 几所台湾大学展示了一种新的晶体管架构,即 LFET。在某些方面,这是 IBM 的 VTFET 和 CFET 的组合。pFET 垂直放置在水平放置的 nFET 之上。LFET 中的“L”不代表任何东西,它只是这个结构的形状。LFET 在密度方面的改进较少,但它们更易于实施,也更容易调整。与栅极的接触也可以更容易地形成。  这些器件使用 3 个 PMOS 和 3 个 NMOS 纳米片进行模拟。LFET 的压降略高。但是,它们的功耗和电阻也较低。  先进的逻辑技术:晶体管架构 金属堆叠的缩放在每个芯片设计中都至关重要,因为它通常是限制因素。然而,最近的技术进步阻碍了金属堆叠的缩放。当电流通过金属互连时,它会产生热量并导致金属原子流动,称为电迁移。随着时间的推移,这种流动会导致空隙和小丘,导致设备电阻增加,并最终导致故障。 随着电流密度的增加,铜互连尺寸的缩小加剧了这个问题,导致更大的热量产生和电迁移,以及互连与晶体管开关相比更多的功率损耗。为解决这个问题,引入了氮化钽势垒,但随着互连不断缩小,势垒尺寸越小,在较低金属层中所占的比例就越大,从而阻碍了缩放工作。 在 Intel 的 10nm 和 Intel 7 节点中,钴被用于最底层的金属堆栈,尽管这已经在 Intel 4 中退回了。Ruthenium 也被用于他们的 10nm 和 7nm 节点中,并且越来越成为每个人都希望采用的材料超过。 一、IBM Subtractive Ru Interconnect 由用于 EUV 双图案化的新型图案化解决方案和带有嵌入式气隙集成的 TopVia 实现,用于后 Cu 互连缩放 IBM Research 和三星展示了他们使用钌 (Ru) 代替铜的新型互连。Ru 与钴很像,不需要势垒并且可以缩放到更小的宽度,而不会获得天文数字的电阻和电容。 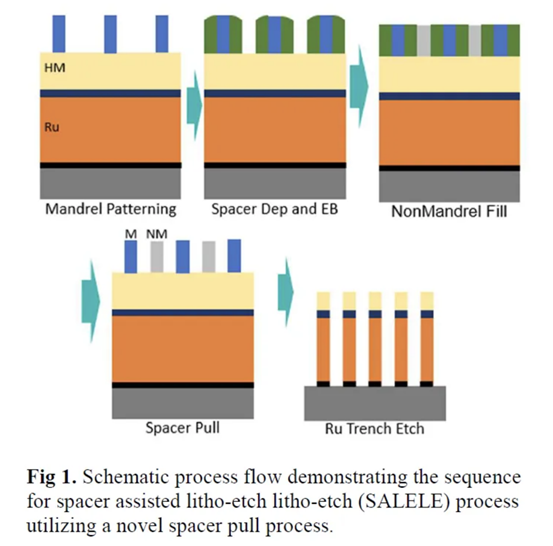 尽管可以使用类似于铜的双镶嵌工艺制造 Ru 互连,但他们在这项新研究中使用了减法图案化。这需要使用带 EUV 的间隔辅助 LELE (SALELE)。这使他们能够形成金属间距为 18 纳米的互连,比台积电 N3E 上的 MMP 减少了 22%。 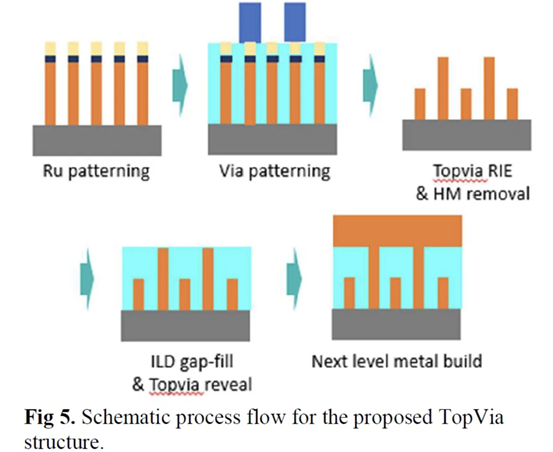 它们还具有 4:1 的高纵横比,以增加电容为代价降低了 20% 的电阻。由于 SALELE 在互连顶部的金属层之间构建通孔,因此用空气填充导线之间的空间要容易得多,这是 ak=1 时可用的最佳电介质。与 k<2.7 的低 k 电介质相比,这是一个显着的变化,可以将电容降低 30% 以上。 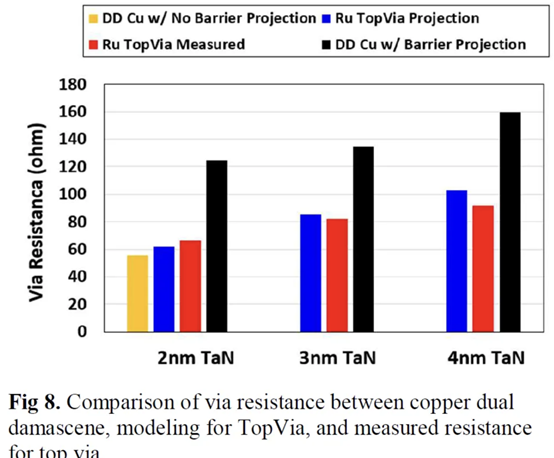  二、Applied Materials Tungsten MOL 局部互连创新:材料、工艺和系统协同优化 3nm 节点及更高节点 Applied Materials 还展示了他们使用钨 (W) 的新互连。目前,钨是通过化学气相沉积 (CVD) 沉积的,并具有由氮化钛制成的阻挡层。由于 3D NAND,Lam Research 在钨沉积方面的市场份额处于领先地位,但 Tokyo Electron 和 Applied Materials 也在运营。这项新研究展示了不需要衬垫的选择性 W。当使用钨时,目前的衬里通常是 TiN。 如果这项技术成功,它可以在所有高级逻辑节点中采用,这对应用材料公司来说将是一个巨大的利好。  与 Ru 非常相似,这很可能是允许未来互连扩展的候选者。通过这项新的创新,他们能够将通孔和链条电阻降低 40%。  他们还表明,该工艺可使相同电压下的性能提高多达 13%,在相同功率下性能提高 8.7%,标准电池面积减少 1.4%。像这样的小创新复合在一起,以保持半导体缩放的轮子转动。  这对于具有背面供电网络的未来设备的信号侧互连具有巨大潜力!  高级逻辑技术:静态随机存取存储器 (SRAM) 一、具有双层转移 Ge/2Si CFET 和 IGZO 传输门的 3-D 异构 6T SRAM 的集成设计和工艺,可将单元尺寸缩小 42% 正如台积电的 N3E 工艺所示,SRAM 缩放变得异常困难。虽然持续的收益将继续难以实现,但 SRAM 有一些最后的技巧。向 GAAFET 和 CFET 的转变应该能够使 SRAM 大幅缩小,每个缩小 30-40%。台湾多所大学展示了一种带有 CFET 的 SRAM 位单元设计,该设计仅使用 2 个晶体管的面积来构建 6 晶体管 SRAM 位单元。他们通过顺序堆叠实现了这一点。  有了这个,他们能够将面积减少 42%。根据他们的研究,新的 bitcell 设计在空闲时消耗的功率减少了 100 倍!  与转移到 3D 领域的其他潜在 SRAM 新设计(包括来自 IMEC 的设计)相比,这是非常有趣的。鉴于台积电的 N3E 没有 SRAM 微缩,这项研究至关重要。  先进封装 台积电、英特尔和三星在 IEDM 上提供了他们先进封装技术的更新。随着前沿节点的成本进一步增加,先进封装只会变得越来越重要。 一、TSMC使用有机中介层 (CoWoS-R) 的异构和小芯片集成 台积电对 CoWoS-R 进行了一些小更新。尽管这主要是对现有信息的重申,但台积电表示他们可以采用 2μm/2μm 或 1μm/1μm 的 L/S 进行封装。他们还展示了它被用于将 HBM3 链接到小芯片。  二、英特尔 EMIB 3 英特尔展示了其两种封装技术,EMIB 和 Foveros Direct。凭借其第三代 EMIB,EMIB 显着将其贴装精度提高了 3 倍以上。借助新工艺,在为 TCB 工艺加热时,die的移动量也减少了约 50%。他们还展示了带有使用 AIB 2.0 的 FPGA 封装。根据 DARPA CHIPS 计划,使用 36 μm的第三代 EMIB 连接到 Texas Instruments 的模拟前端芯片。根据显示的横截面,L/S 似乎是 2μm/2μm,与 2016 年 ECTC 的论文相当。这比他们的产品(如 Stratix 10 和 Sapphire Rapids)中的 5μm/5μm L/S 有所改进.  他们还在实际论文中展示了一些提高良率的技术。 三、Foveros 直接重组晶圆键合晶圆 英特尔第一代Foveros Direct 的间距为 9μm,密度比使用微凸块的 Foveros 提高了 4 倍。第二代的间距为 3μm,密度又提高了 4 倍。当然,这些是最小间距,正如AMD 在 Zen 3 上的 3D V-Cache 技术所展示的,最小间距并不总是被使用。如果英特尔能够坚持其路线图并兑现承诺,它可能会赶上台积电的第 4代SoIC ,同样是 3μm 的间距。 据英特尔称,第 2代将效率提高了约 20%。他们还声称这将允许近乎整体的设计,几乎没有或没有功率、面积和延迟开销。我们觉得这很难相信,但进一步扩大规模将有助于这三个领域。最后,英特尔还展示了一些芯片系统的概念,该芯片系统使用多种不同的封装方法并堆叠了很多层。  英特尔的工艺最有趣的地方在于它是一种重组晶圆键合晶圆。  他们将其称为准单片芯片 (QMC)。 四、三星先进封装、混合键合逻辑4umm和混合键合HBM 一段时间以来,三星在先进封装领域一直处于落后状态,其封装解决方案未能获得重大关注,尽管他们正在大力投资以争取份额。它的 X-Cube 计划在 2024 年投产,采用微凸块,比台积电和英特尔落后多年,而在 2026 年采用混合键合,又比台积电和英特尔落后多年。他们的封装解决方案以 Advanced Packaging Fab Solutions (APFS) 为品牌。  I-Cube 是三星的硅中介层技术,类似于 CoWoS-S 。第 4代支持 8个HBM 封装和 3 倍光罩尺寸,比台积电晚了大约 1 年。据说下一代支持 12 HBM 封装和 4x 标线尺寸。三星还展示了采用混合键合的 12Hi HBM,这是他们在 2021 年实现的。提醒一下,SK 海力士在 2021 年公开展示了采用混合键合的 16Hi HBM。  我们预计百度仍将是唯一使用这些技术的大客户。三星的混合键合 X-Cube 被证明具有 4μm 间距,如果到 2026 年投产,这可能会大大缩小差距。但是,它很可能只会在晚些时候投产。  五、用于小芯片设计和异构集成封装的 Unimicron 混合基板 欣兴还展示了一些先进的封装。他们在 PID 和 ABF 基板上使用了 55μm 的微凸点间距,并对它们进行了比较。他们展示了一个 3 金属层设计,每个金属层具有不同的间距和线/间距,分别低至 3μm 和 2/2μm。虽然这种封装与 TSMC 或 Intel 的 HVM 相比没有那么先进,但它仍然表明 OSAT 正在研究自己的解决方案。  Unimicron 是 Intel、AMD 和许多其他公司的基板供应商。 六、面向小芯片和异构集成的 ASE 先进封装技术平台 近年来,日月光一直在改进其封装选择组合,以保持与台积电和其他公司的竞争力。在 IEDM 上,他们提供了许多封装选项的摘要。Fanout Chip on Substrate (FOCoS) 有多种形式,例如 FOCoS-Chip First (FOCoS-CF) 和 FOCoS-Chip Last (FOCoS-CL)。这些之间的区别类似于台积电对CoWoS 和 InFO的区分。 FOCoS-CF 支持 4 个重分布层 (RDL),线距/间距为 2/2μm。他们展示了一个test vehicle,在 47.5x47.5mm 2封装上有两个 30x28mm 2芯片。FOCoS-CL 具有 4 层具有相同线/间距的 RDL。它具有 55μm 的微凸点间距,类似于英特尔 Sapphire Rapids 中 EMIB 的间距。所示的测试车辆有一个尺寸为 30x28mm 2的 ASIC 裸片,以及在 47.5x47.5mm 2封装上的两个 HBM 堆栈。  ASE 还展示了 FOCoS-Bridge (FOCoS-B)。这涉及使用嵌入式硅桥,线/间距小至 <0.8/0.8μm。他们的网站声明它下降到 0.6/0.6μm。我们认为 FoCoS-B 是 SPIL 在被 ASE 收购之前开发的 FOEB 的重命名版本。他们的测试车辆展示了具有 0.8/0.8μm 线/间距的 FoCoS-B。它有 2 个 ASIC 芯片和 8 个 HBM2e 堆栈。  |



